Comment les outils d’IA génèrent une dette technique dans les systèmes IoT – et que faire à ce sujet
le premier lancement d’Ariane 5 a eu lieu, un nouveau lanceur européen lourd conçu pour transporter des charges utiles en orbite terrestre basse. La fusée a explosé moins de 40 secondes après le décollage. C’était causé par des erreurs de spécification et de conception dans le logiciel du système de navigation inertielle. Un module logiciel avait été réutilisé de la version précédente d’Ariane 4 sans vérifier si ses contraintes étaient adaptées au nouvel environnement. C’est devenu l’une des erreurs logicielles les plus coûteuses de l’histoire.
Pourquoi est-ce que je rappelle un événement d’il y a trente ans dans un texte sur la dette technique générée par les outils d’IA ? Parce que cela nous aide à nous rappeler une vérité simple : dans les systèmes complexes, ce qui est dangereux n’est pas seulement le « mauvais code », mais aussi le code qui semble acceptable mais qui ne correspond pas au contexte. Les assistants IA reproduisent un problème similaire ?.
En tant que spécialiste du domaine de l’IIoT, notamment de la maintenance prédictive, je constate ceci : les outils d’IA génèrent rapidement du code fonctionnel qui semble approprié pour une tâche locale, mais ils ne vérifient pas leurs propres hypothèses au niveau de l’ensemble du système. Dans l’IIoT, cela signifie qu’une solution peut être correcte au niveau d’une fonction ou d’un service individuel, mais ne pas tenir compte des contraintes liées au matériel spécifique, au flux de données, aux limites architecturales ou aux conditions de fonctionnement réelles des appareils. En conséquence, un code localement correct devient une source de pannes systémiques et de correctifs coûteux, entraînant un développement plus lent de l’ensemble de la plateforme.
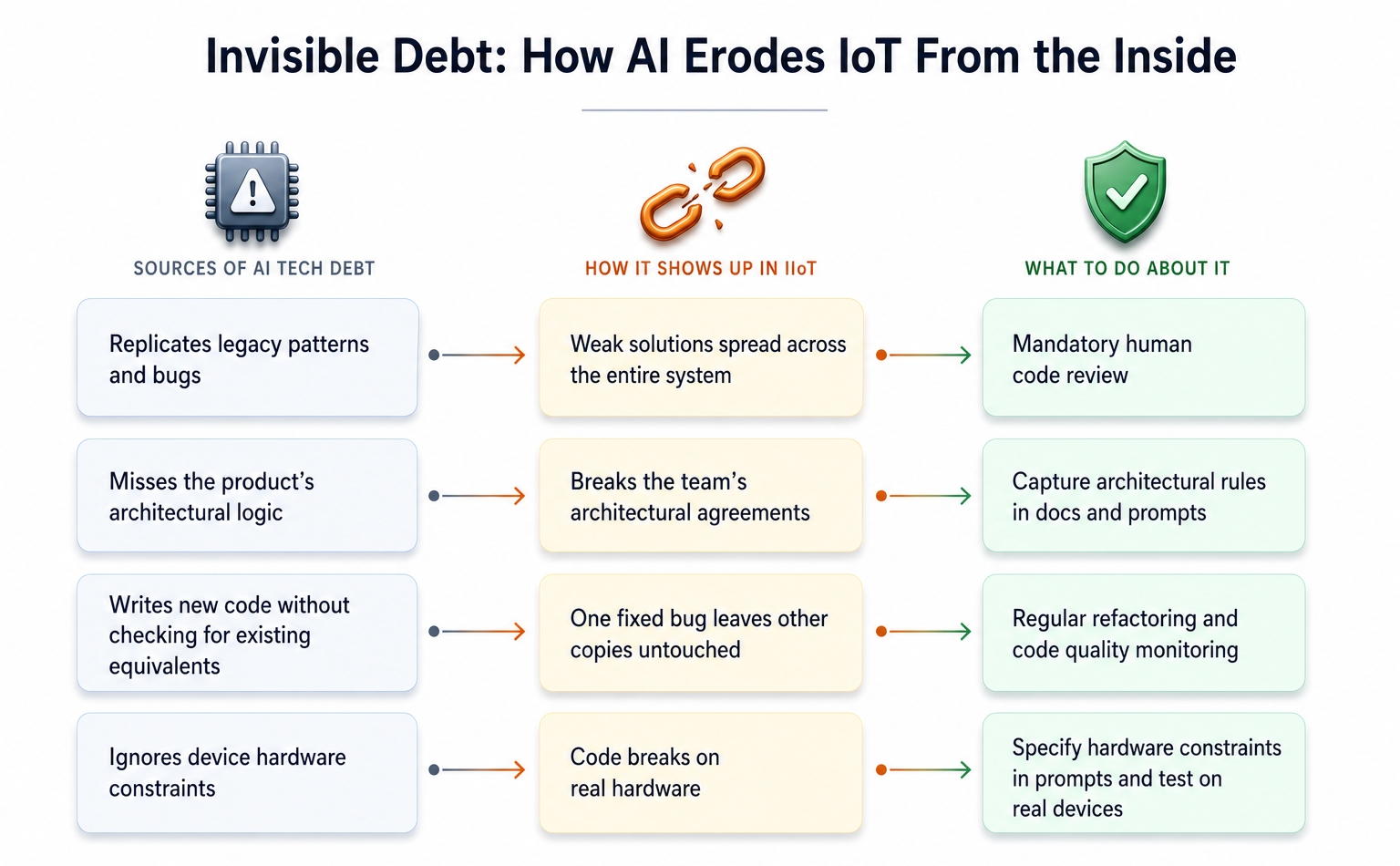
Quatre types de dette technique de l’IA
La dette technique est toute décision qui accélère les choses maintenant mais qui coûte plus cher plus tard. Je soulignerais quatre mécanismes principaux par lesquels les outils d’IA peuvent générer une dette technique.
Reproduire des modèles et des erreurs hérités
Un assistant IA génère des suggestions basées sur le contexte du code qu’il voit dans l’environnement actuel et n’est pas toujours en mesure d’identifier des problèmes de conception ou d’architecture plus larges. GitHub explicitement remarques que Copilot a une portée limitée, s’appuie sur le contexte du code en cours d’écriture et peut également hériter des erreurs et des biais des référentiels existants. Par conséquent, si un projet contient déjà des approches obsolètes, un stockage de données redondant ou des « solutions de contournement » au lieu de solutions architecturales appropriées, l’IA friandises cela constitue la norme et continue de la reproduire. En ce sens, cela fonctionne comme une chambre d’écho : les mauvaises pratiques sont non seulement préservées, mais mises à l’échelle plus rapidement.
Et ce n’est pas seulement un risque théorique. Une étude de 304 000 commits vérifiés générés par l’IA dans plus de 6 000 référentiels réels a montré que plus de 15 % des validations de chacun des cinq outils d’IA évalués présentaient au moins un problème de qualité de code, et qu’un quart de ces problèmes restaient non résolus dans la version finale du code.
Dans les systèmes IoT, ce mécanisme est particulièrement dangereux car un modèle hérité reste rarement un problème local au sein d’un seul module. Si un assistant reproduit une solution faible dans le code du micrologiciel, les services de passerelle ou le traitement de télémétrie, elle se propage rapidement sur l’ensemble de la chaîne, depuis la couche appareil jusqu’au côté cloud du système.
Des « solutions rapides » sans connaissance de l’architecture
L’IA est très efficace pour résoudre les tâches d’ingénierie locales : elle peut générer rapidement des tests, écrire du code passe-partout ou créer des points de terminaison CRUD standard. Cependant, c’est le cas je ne vois pas l’architecture : quelles bases de données sont utilisées pour quelles données, quelles limites sont en place et comment les composants interagissent les uns avec les autres. Une étude d’Ox Security portant sur 300 projets open source, dont 50 entièrement ou partiellement générés par l’IA, trouvé que le code était fonctionnel mais manquait systématiquement de jugement architectural.
En conséquence, l’IA peut créer une dette technique même sans reproduire les modèles hérités. Si les règles architecturales ne sont pas explicitement énoncées (dans la documentation, les enregistrements de décision ou même dans les invites elles-mêmes), le modèle optimise la tâche locale de manière isolée. Dans les systèmes IIoT complexes, cela ressemble à ceci : les séries chronologiques, les données de référence et les journaux sont stockés dans différentes bases de données, chacune optimisée pour sa propre charge de travail – mais l’assistant, lorsqu’on lui demande de stocker de nouvelles données, ignore cette topologie et génère du code qui viole progressivement les accords architecturaux établis par l’équipe.
Duplication de la logique et complexité accrue de la maintenance
Un assistant IA ne sait pas que le code dont il a besoin existe déjà ailleurs dans le système, il écrit donc une nouvelle version. Le résultat est plusieurs implémentations indépendantes de la même logique — et lorsqu’un changement est nécessaire, les développeurs passent du temps à rechercher tous les doublons.
Une analyse de 211 millions de lignes de code modifiées de 2020 à 2024 par GitClear a montré que la part du code dupliqué est passée de 8,3 % à 12,3 %. 2024 est devenue la première année au cours de laquelle la quantité de code dupliqué a dépassé la quantité de refactoring. Les outils d’IA vont probablement accélérer encore cette tendance. Ils permettent d’insérer un nouveau bloc de code d’une simple pression sur une touche, mais il est peu probable qu’ils suggèrent de réutiliser une fonction similaire provenant d’une autre partie du projet – en partie à cause de la contexte limité à leur disposition.
Dans les systèmes IoT, si la même logique (par exemple, analyse de paquets ou validation de connexion) est implémentée indépendamment à plusieurs endroits, corriger un bug dans une copie sans trouver les autres peut conduire à ce que les appareils sur le terrain se comportent différemment sous le même signal d’entrée. La résolution de telles incohérences nécessite non seulement de modifier le code, mais également de synchroniser les mises à jour du micrologiciel sur des milliers d’appareils simultanément.
Ignorer les contraintes matérielles
Les appareils IoT ne disposent pas des ressources illimitées des services cloud. Une passerelle dispose d’une quantité spécifique de mémoire, d’une bande passante réseau limitée et d’un budget de batterie fixe. Un assistant IA peut prendre en compte ces contraintes, mais seulement si le développeur les spécifie explicitement.
Si cela ne se produit pas, l’assistant génère des solutions pour l’environnement sur lequel il a été principalement formé : des systèmes basés sur le cloud et sur serveur où la mémoire est effectivement illimitée et le réseau est stable. Le résultat est prévisible : réessai sans fin des boucles sans délai d’attente, des formats de données textuels « lourds » au lieu de protocoles binaires compacts et un code qui se compile correctement mais ne tient pas compte des spécificités matérielles d’une carte particulière.
Une solution qui fonctionne bien dans un émulateur peut échouer lorsqu’elle est exécutée sur un périphérique physique doté de ressources limitées.

Que faire pour que l’IA ne crée pas de dette technique dans un projet
L’IA dans les systèmes IoT nécessite une discipline d’ingénierie plus stricte que le développement sans elle. Je décrirai quatre pratiques qui aident mon équipe à garder la qualité du code sous contrôle.
Révision obligatoire du code humain
Cela semble évident, mais dans la pratique, lorsque l’on travaille avec des assistants IA, il existe une tentation d’accepter le code généré sans analyse approfondie, d’autant plus que plus de la moitié des développeurs dire le code semble généralement « correct ». Selon un étude sur plus de 1 100 développeurs, seuls 48 % examinent toujours le code généré par l’IA avant de le valider.
L’examen doit vérifier non seulement si le code est compilé, mais également s’il prend en compte les contraintes de l’environnement matériel spécifique, s’il existe une duplication de la logique et si la solution s’aligne sur l’architecture globale du système.
Cependant, la révision manuelle du code présente un problème : les assistants IA augmentent le volume et la vitesse du nouveau code plus rapidement que les équipes ne peuvent s’adapter. Selon LeadDev, 29 % des organisations sont déjà dépenses plus de temps sur la révision du code qu’auparavant. Cela signifie que dans le développement basé sur l’IA, l’examen humain crée rapidement un goulot d’étranglement s’il n’est pas renforcé par des garde-fous et des contrôles automatisés.
Restreindre l’IA aux parties critiques du projet
Tous les codes ne sont pas également critiques. Il vaut la peine de définir explicitement des « zones interdites » pour la génération autonome d’IA : traitement des paquets de périphériques entrants, logique d’autorisation, gestion des interruptions et logique de minuterie de surveillance, ainsi que tout code qui interagit directement avec le micrologiciel.
Un critère de séparation simple est le suivant : si une erreur dans ce code nécessite une mise à jour du micrologiciel sur les appareils de terrain ou brise l’intégrité des données de tous les clients simultanément, alors l’IA ne doit agir que comme un assistant sous supervision humaine, et la décision finale doit revenir au développeur qui comprend le contexte du système.
Refactorisation et surveillance régulières
À mesure que la vitesse de production du code augmente, la vitesse à laquelle les problèmes cachés s’accumulent augmente également. Refactorisation régulière devient pas seulement une bonne pratique, mais une nécessité. D’après mon expérience, l’architecture doit être revue au moins une fois tous les six mois, en accordant une attention particulière aux domaines dans lesquels le code généré par l’IA peut avoir introduit des problèmes cachés.
En parallèle, la surveillance est nécessaire, mais dans l’IoT, elle a une portée plus large que dans un système backend classique. D’après mon expérience, au-delà de la dégradation des performances au niveau du service montrée par des outils comme Datadog ou AWS CloudWatch, il est essentiel de suivre l’état des appareils eux-mêmes : consommation de mémoire périphérique, latence entre l’appareil et la passerelle et anomalies de télémétrie. C’est là que le code généré par l’IA avec des contraintes matérielles non prises en compte a tendance à faire surface en premier.
Conclusion
La dette technique existait bien avant que l’utilisation de l’IA ne devienne courante. Cependant, l’IA peut accélérer son accumulation, en particulier dans les environnements où il n’existe pas de culture de documentation, de gouvernance architecturale et de refactorisation régulière. Dans les systèmes IoT, le coût de cette accélération se mesure non seulement en temps de développement, mais également en fiabilité de milliers d’appareils physiques.