
Comment étudier la monotonie et la stabilité des variables dans un modèle de notation à l’aide de Python
Je tiens à remercier tous ceux qui ont pris le temps de lire et de participer à mon article. Votre soutien et vos commentaires sont vraiment appréciés.
Vous pouvez reproduire l’analyse sur mon dépôt GitHub : Notation de crédit avec Python.
il ne s’agit pas seulement de former un algorithme d’apprentissage automatique et d’évaluer ses performances avec une AUC ou un coefficient de Gini.
De nombreux débutants en modélisation se précipitent dans la formation de modèles, sautant les étapes cruciales qui déterminent si un modèle est véritablement robuste et interprétable. Cet enthousiasme, qui ne dure que quelques minutes — juste le temps que les mesures de performance apparaissent à l’écran — occulte souvent le travail plus approfondi et rigoureux qui précède cette étape.
En risque de crédit, la qualité d’un modèle dépend fortement des variables qu’il utilise. Une variable qui semble prédictive dans un ensemble de données d’entraînement peut se comporter de manière incohérente dans le temps ou entre différentes populations. Si nous ignorons cela, nous risquons de construire un modèle qui fonctionne bien en développement mais échoue en production.
Cela soulève trois questions fondamentales. Les variables sélectionnées présentent-elles un risque de crédit constant dans le temps ? L’évolution de ce risque reste-t-elle stable d’année en année ? La distribution de ces variables reste-t-elle comparable dans les ensembles de données de formation, de test et hors période ?
– Je définis d’abord les notions de monotonie et de stabilité dans le credit scoring.
– Ensuite, j’applique ces concepts aux sept variables sélectionnées dans mon article précédent.
– Enfin, j’évalue la stabilité des ensembles de données à l’aide de l’indice de stabilité de la population (PSI) au fil des années et des ensembles de données d’entraînement, de test et hors du temps.
Présentation des données
Dans mon article précédent, j’ai présenté une méthode simple qui combine l’analyse des relations variables avec la validation croisée pour sélectionner de manière robuste les variables pour un modèle de notation. Cette méthode est simple à comprendre, facile à mettre en œuvre et puissante, surtout lorsqu’elle est combinée à la régression logistique, qui reste le modèle de référence en matière de credit scoring.
J’ai retenu sept variables après le processus de sélection :
Cinq chiffres ceux [person_income, person_age, person_emp_length, loan_int_rate, and loan_percent_income]
et deux catégoriques ceux [person_home_ownership and cb_person_default_on_file].
La question que je pose maintenant est de savoir si ces variables sont vraiment pertinentes pour estimer les paramètres du modèle de notation final, et comment je peux interpréter la direction du risque de chaque variable.
Définir la monotonie et la stabilité
Monotonie fait référence à l’analyse de l’orientation du risque d’une variable présélectionnée. Pour une variable continue, cela répond à la question suivante : lorsque la valeur de la variable augmente ou diminue, le risque de crédit augmente-t-il ou diminue-t-il en conséquence ?
Par exemple, dans le contexte d’une entreprise, nous nous attendons à ce que lorsque les revenus d’une entreprise augmentent, sa situation financière s’améliore. A l’inverse, lorsque ses revenus diminuent, sa situation financière se dégrade. C’est la direction du risque.
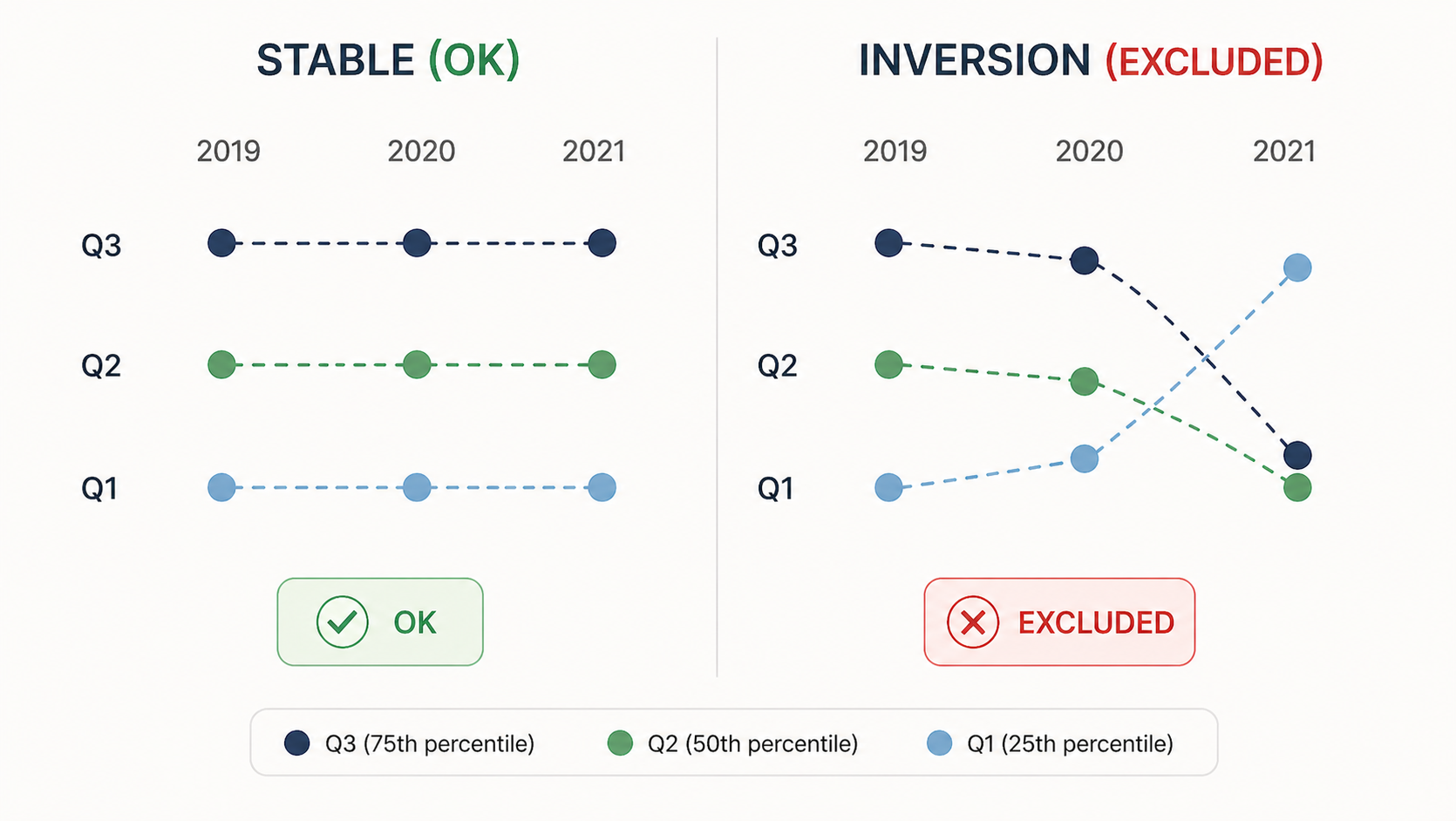
Stabilité va encore plus loin. Il répond à la question : cette orientation du risque est-elle systématiquement respectée sur plusieurs années, ou observons-nous des inversions de risque ? Une inversion du risque se produit lorsque, malgré une augmentation des revenus, la situation financière se détériore – ou vice versa. La stabilité donne une vision à long terme du comportement de la variable et soutient une prise de décision éclairée.
En credit scoring, on étudie à la fois la monotonie des variables et leur stabilité dans le temps. Nous étudions également la stabilité des distributions variables entre années consécutives et entre les ensembles de données d’entraînement, de test et hors du temps.
Monotonie et stabilité des variables
Cette analyse constitue une étape de présélection. Si une variable présente une inversion du risque au fil du temps, il faut soit la traiter, soit la supprimer du modèle. Pour les variables continues, le traitement consiste généralement à discrétiser la variable et à agréger ses classes. Pour les variables catégorielles, on peut combiner directement certaines catégories.
Définir l’orientation du risque
La première étape consiste à attribuer une direction de risque à chaque variable.
Pour un variable continueon attribue un signe « + » si l’on s’attend à ce qu’une augmentation de la variable entraîne une augmentation du risque de crédit. Nous attribuons le signe « – » si nous prévoyons qu’une augmentation entraîne une diminution du risque de crédit.
Pour un variable catégorielle binairenous attribuons un signe « + » si le passage de la catégorie la moins risquée à la catégorie la plus risquée augmente le risque. Nous attribuons un signe « – » si cela diminue le risque.
Pour un variable multi-catégoriesnous n’attribuons pas de signe binaire. Au lieu de cela, nous classons les catégories du moins risqué au plus risqué en fonction de leur taux de défaut empirique. La catégorie avec le taux de défaut le plus faible est la moins risquée ; celui avec le plus élevé est le plus risqué. Nous validons ensuite ce classement auprès d’experts métiers.
Le tableau ci-dessous résume l’orientation attendue du risque pour chaque variable continue étudiée. Un « + » signifie qu’une augmentation de la variable devrait augmenter le risque de crédit et donc la probabilité de défaut calculée. Un « – » signifie le contraire.

Je fais ici deux commentaires spécifiques. Pour personnagel’âge est une variable sensible qui peut discriminer les contreparties. Nous nous attendons à ce que les contreparties très jeunes et très âgées comportent un risque plus élevé, ce qui rend difficile l’attribution d’une direction unique. Nous laissons donc les données révéler la structure du risque. Pour personne_home_ownershipla variable a plusieurs catégories, ce qui rend tout aussi difficile l’attribution d’une direction binaire a priori. Nous nous attendons à ce que la catégorie LOYER comporte le risque le plus élevé, suivie de l’HYPOTHÈQUE, puis du PROPRE, la catégorie AUTRE capturant les contreparties dans des situations de logement plus ambiguës. Nous laissons les données confirmer cet ordre.
Approche pratique
En pratique, nous évaluons le taux de défaut empirique au fil du temps pour des valeurs définies des variables explicatives. Pour les valeurs que nous définissons comme risquées, nous nous attendons à des taux de défaut plus élevés. Pour les valeurs que nous définissons comme moins risquées, nous nous attendons à des taux de défaut plus faibles.
Pour variables continuesnous les discrétisons à l’aide de quantiles. À l’aide des terciles — Q1, Q2 et Q3 — nous calculons le taux de défaut de chaque catégorie pour chaque année. Si une variable a un signe « + », le taux de défaut au T1 doit être inférieur à celui du T2, qui doit être inférieur à celui du T3, pour chaque période. Graphiquement, la courbe du T3 se situe au-dessus de la courbe du T2, qui se situe au-dessus de la courbe du T1.

Pour variables catégoriellesnous calculons le taux de défaut de chaque catégorie pour chaque période. La courbe de la catégorie la plus risquée doit systématiquement se situer au-dessus des courbes de toutes les autres catégories.
Application : Monotonie et stabilité des sept variables
Nous appliquons ce cadre aux sept variables présélectionnées. La répartition de la variable « par défaut » par année dans l’ensemble de formation est la suivante :

Variables continues
Nous discrétisons les variables continues en terciles sur l’ensemble d’apprentissage.
Revenu de la personne La monotonie du risque est respectée dans toutes les périodes. Les contreparties ayant les revenus les plus faibles affichent les taux de défaut les plus élevés toutes les années. Nous n’observons aucune inversion du risque.

Âge de la personne La monotonie du risque n’est pas respectée. Nous observons une inversion du risque, et le deuxième trimestre n’est pas présent toutes les années. Cette variable n’a pas le pouvoir prédictif permettant de différencier les bonnes et les très bonnes contreparties. Je l’exclus de toute modélisation ultérieure.

Durée de l’emploi La monotonie du risque est globalement respectée toutes les années.

Taux d’intérêt La monotonie du risque est respectée pour toutes les années.

Pourcentage de revenu du prêt La monotonie du risque est globalement respectée sur toutes les années pour cette variable.

Variables catégorielles
Valeur par défaut historique (cb_person_default_on_file) La monotonie du risque est respectée. Les contreparties ayant un historique de défaut affichent des taux de défaut plus élevés sur toutes les périodes. Ce résultat est tout à fait cohérent.

Propriété résidentielle (person_home_ownership) La monotonie du risque est respectée au niveau global mais pas au niveau annuel pour 2016, 2017 et 2018. 
Dans cette situation, nous avons plusieurs options. Je choisis de regrouper la variable en trois catégories : PROPRE, HYPOTHÈQUE et (LOCATION + AUTRE). Après regroupement, la monotonie du risque est globalement respectée.
Résumé
Cette analyse de monotonie m’amène à exclure la variable person_age, dont la stabilité du risque n’est pas respectée. Je conserve les six variables restantes pour l’étape suivante.
Stabilité de l’ensemble de données
J’étudie maintenant la stabilité des distributions variables. L’objectif est de garantir que la distribution de chaque variable reste cohérente au fil des années et entre les ensembles de données d’entraînement, de test et hors du temps.
L’indice de stabilité de la population (PSI)
Nous utilisons le PSI – un indicateur pratique largement utilisé dans la notation du crédit – pour mesurer les changements de répartition. Il s’applique directement aux variables catégorielles. Pour les variables continues, nous les discrétisons d’abord. Dans cet article, j’utilise des terciles pour les variables continues.
Pour chaque variable, nous calculons la proportion d’observations dans chaque groupe ou catégorie pour les deux ensembles de données. Le PSI compare ensuite, case par case, les proportions observées dans le jeu de données de référence par rapport au jeu de données cible, à l’aide de la formule logarithmique suivante :
Ici, pᵢ et qᵢ désignent les proportions dans le bac i des ensembles de données de référence et cible, respectivement. Dans cet article, j’explique clairement comment utiliser cet indicateur. Lorsqu’elle est inférieure à 10 %, la variable est considérée comme stable. Lorsqu’elle est inférieure à 25 %, aucun changement significatif n’est observé.
Stabilité d’une année sur l’autre
J’évalue si la distribution de chaque variable a changé d’une année à l’autre.

Toutes les variables sont stables dans le temps — aucun dépassement de seuil n’est observé (PSI inférieur à 10 %).
Stabilité de l’ensemble de données
J’évalue la stabilité des distributions variables sur les trois ensembles de données, en testant trois scénarios :
- Entraîner contre tester,
- Train vs Hors du temps,
- Et test vs hors délai.

Aucune violation du seuil n’est observée dans tous les scénarios, ce qui confirme que les facteurs de risque sélectionnés sont stables entre les ensembles d’estimation et d’évaluation.
Conclusion
Dans cet article, j’ai présenté un cadre rigoureux pour étudier la monotonie et la stabilité dans un modèle de notation. J’ai montré comment attribuer une direction de risque à chaque variable, comment valider cette direction au fil des années et comment détecter les changements de distribution à l’aide du PSI. Cette étape, souvent ignorée dans la pratique, est essentielle pour garantir que le modèle que je construis est non seulement performant, mais également robuste, interprétable et fiable dans le temps.
Dans mon prochain article, je présenterai l’estimation du modèle de notation final à l’aide des six variables retenues.
Crédits images
Toutes les images et visualisations de cet article ont été créées par l’auteur en utilisant Python (pandas, matplotlib, seaborn et plotly) et Excel, sauf indication contraire.
Références
[1] Lorenzo Beretta et Alessandro Santaniello.
Algorithmes d’imputation du voisin le plus proche : une évaluation critique.
Bibliothèque nationale de médecine, 2016.
[2] Nexialog Conseil.
Traitement des données manquantes dans le milieu bancaire.
Document de travail, 2022.
[3] John T. Hancock et Taghi M. Khoshgoftaar.
Enquête sur les données catégorielles pour les réseaux de neurones.
Journal du Big Data, 7(28), 2020.
[4] Melissa J. Azur, Elizabeth A. Stuart, Constantine Frangakis et Philip J. Leaf.
Imputation multiple par équations chaînées : qu’est-ce que c’est et comment ça marche ?
Revue internationale des méthodes de recherche psychiatrique, 2011.
[5] Majid Sarmad.
Analyse de données robuste pour les plans expérimentaux factoriels : méthodes et logiciels améliorés.
Département des sciences mathématiques, Université de Durham, Angleterre, 2006.
[6] Daniel J. Stekhoven et Peter Bühlmann.
MissForest : Imputation de valeur manquante non paramétrique pour les données de type mixte.Bioinformatique, 2011.
[7] Supriyanto Wibisono, Anwar et Amin.
Détection d’anomalies météorologiques multivariées à l’aide de l’algorithme de clustering DBSCAN.
Journal of Physics : série de conférences, 2021.
[8] Laborda, J. et Ryoo, S. (2021). Sélection de fonctionnalités dans un modèle de notation de crédit. Mathématiques, 9(7), 746.
Données et licences
L’ensemble de données utilisé dans cet article est sous licence Creative Commons Attribution 4.0 International (CC BY 4.0) licence.
Cette licence permet à quiconque de partager et d’adapter l’ensemble de données à n’importe quelle fin, y compris un usage commercial, à condition qu’une attribution appropriée soit attribuée à la source.
Pour plus de détails, consultez le texte officiel de la licence : CC0 : domaine public.
Clause de non-responsabilité
Toutes les erreurs ou inexactitudes restantes relèvent de la responsabilité de l’auteur. Les commentaires et corrections sont les bienvenus.
You may also like


