
4 fichiers YAML au lieu de PySpark : comment nous laissons les analystes créer des pipelines de données sans ingénieurs
nous avons trois semaines pour expédier un seul pipeline de données. Aujourd’hui, un analyste sans expérience Python le fait en une journée. Voici comment nous y sommes arrivés.
Je m’appelle Kiril Kazlou, ingénieur de données chez Mindbox. Notre équipe recalcule régulièrement les indicateurs commerciaux pour les clients, ce qui signifie que nous construisons constamment des datamarts pour la facturation et l’analyse, en puisant dans des dizaines de sources différentes.
Pendant longtemps, nous nous sommes appuyés sur PySpark pour tous nos traitements de données. Le problème ? Vous ne pouvez pas vraiment travailler avec PySpark sans expérience Python. Chaque nouveau pipeline nécessitait un développeur. Et cela signifiait attendre – parfois pendant des semaines.
Dans cet article, je vais vous expliquer comment nous avons construit une plate-forme de données interne où un analyste ou un chef de produit peut créer un pipeline régulièrement mis à jour en écrivant seulement quatre fichiers YAML.
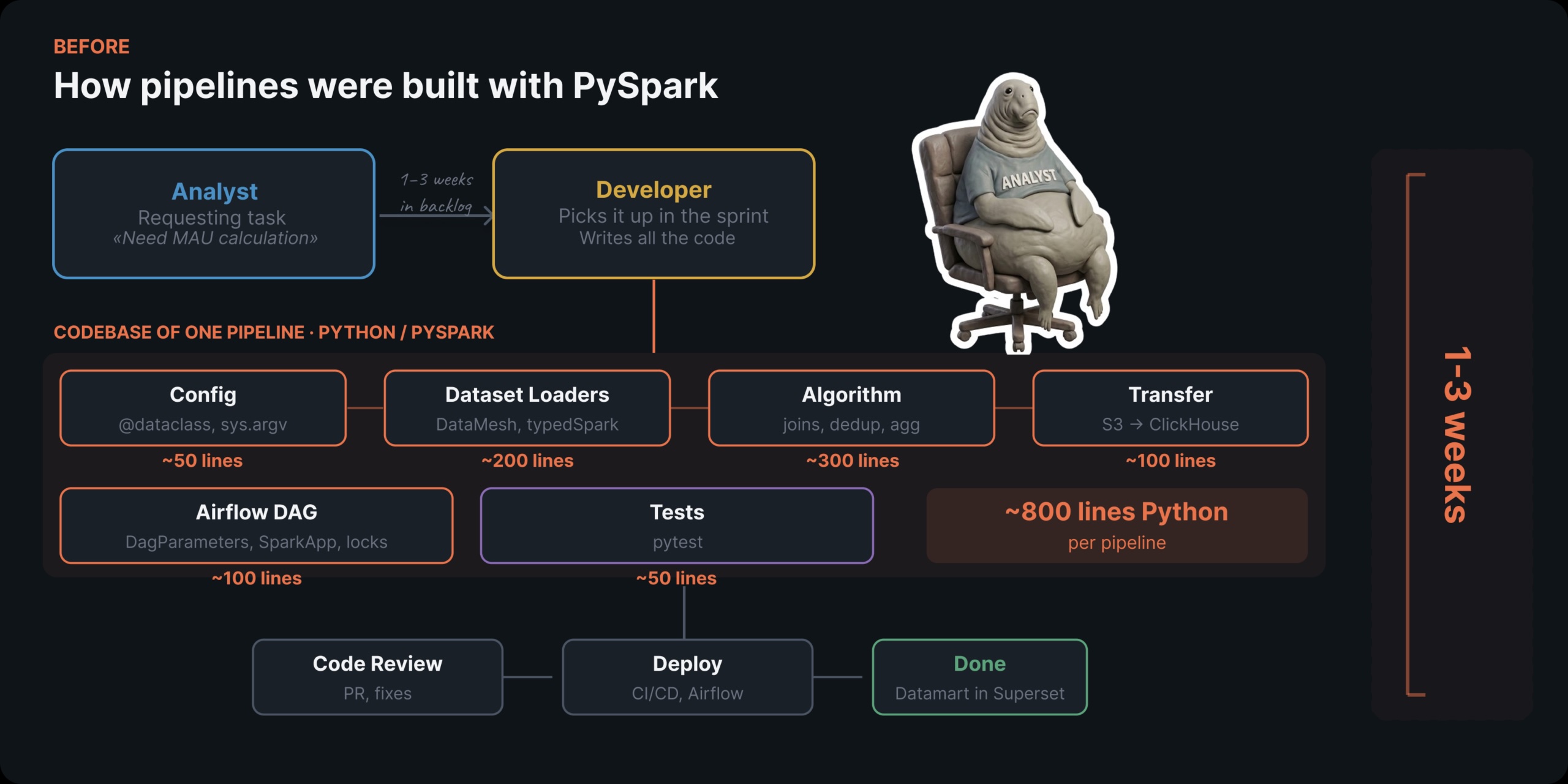
Pourquoi PySpark nous ralentissait
Permettez-moi d’illustrer la douleur avec un exemple de manuel : calculer le MAU (Utilisateurs actifs mensuels).
En apparence, cela ressemble à un simple travail SQL : COUNT(DISTINCT customerId) sur quelques tables sur une fenêtre de temps. Mais en raison de toute la surcharge de l’infrastructure – PySpark, configuration du DAG Airflow, allocation des ressources Spark, tests – nous avons dû le confier aux développeurs. Le résultat ? Une semaine complète rien que pour expédier un compteur MAU.
La livraison de chaque nouvelle mesure prenait une à trois semaines. Et à chaque fois, le processus était le même :
- Un analyste a défini les besoins métiers, trouvé un développeur disponible et lui a transmis le contexte.
- Le développeur a clarifié les détails, écrit le code PySpark, passé en revue le code, configuré le DAG et déployé.
Ce que nous voulions en fait, c’était que les analystes et les chefs de produit – les personnes qui comprennent le mieux la logique métier et maîtrisent SQL et YAML – gèrent cela eux-mêmes. Pas de Python. Pas de PySpark.

Ce que nous avons remplacé PySpark par : YAML et SQL sont tout ce dont vous avez besoin
Pour adopter une approche déclarative, nous avons divisé notre couche de données en trois parties et choisi le bon outil pour chacune :
- dlt (outil de chargement de données) — ingère des données provenant d’API et de bases de données externes dans le stockage d’objets. Configuré entièrement via un fichier YAML. Aucun code requis.
- dbt (outil de construction de données) sur Trino — transforme les données en utilisant du SQL pur. Il relie les modèles via
ref()crée automatiquement un graphique de dépendances et gère les mises à jour incrémentielles. - Flux d’air + Cosmos — orchestre les pipelines. Le DAG Airflow est généré automatiquement à partir de
dag.yamlet le projet dbt.
Nous utilisions déjà Trino comme moteur de requête pour les requêtes ad hoc et l’avions connecté à Superset for BI. Il avait déjà fait ses preuves : pour les requêtes avec une logique standard, il traitait des ensembles de données massifs plus rapidement et avec moins de ressources que Spark. De plus, Trino prend en charge nativement l’accès fédéré à plusieurs magasins de données à partir d’une seule requête SQL. Pour 90 % de nos pipelines, Trino était la solution idéale.

Comment nous chargeons les données : dlt.yaml
Le premier fichier YAML décrit où et comment charger les données pour le traitement en aval. Voici un exemple concret : charger des données de facturation à partir d’une API interne :
product: sg-team
feature: billing
schema: billing_tarification
dag:
dag_id: dlt_billing_tarification
schedule: "0 4 * * *"
description: "Daily refresh of tarification data"
tags:
- billing
alerts:
enabled: true
severity: warning
source:
type: rest_api
client:
base_url: "https://internal-api.example.com"
auth:
type: bearer
token: dlt-billing.token
resources:
- name: tarification_data
endpoint:
path: /tarificationData
method: POST
json:
firstPeriod: "{{ previous_month_date }}"
lastPeriod: "{{ previous_month_date }}"
pricingPlanLine: CurrentPlan
write_disposition: replace
processing_steps:
- map: dlt_custom.billing_tarification_data.map
- name: charges_raw
columns:
staffUserName:
data_type: text
nullable: true
endpoint:
path: /data-feed/charges
method: POST
json:
firstPeriod: "{{ previous_month_date }}"
lastPeriod: "{{ previous_month_date }}"
write_disposition: replace
- name: discounts_raw
endpoint:
path: /data-feed/discounts
method: POST
json:
firstPeriod: "{{ previous_month_date }}"
lastPeriod: "{{ previous_month_date }}"
write_disposition: replaceCette configuration définit quatre ressources à partir d’une seule API. Pour chacun, nous spécifions le point de terminaison, les paramètres de la requête et une stratégie d’écriture — dans notre cas, replace signifie « écraser à chaque fois ». Vous pouvez également ajouter des étapes de traitement, définir des types de colonnes et configurer des alertes.
La configuration entière est 40 lignes de YAML. Sans dlt, chaque connecteur serait un script Python gérant les requêtes, la pagination, les tentatives, la sérialisation au format Delta Table et les téléchargements vers le stockage.
Comment nous transformons les données avec SQL : dbt_project.yaml et sources.yaml
L’étape suivante consiste à configurer le modèle dbt. Avec Trino, cela signifie des requêtes SQL.
Voici un exemple de la façon dont nous configurons le calcul de la MAU. Voici à quoi ressemble la préparation d’un événement à partir d’une seule source :
-- int_mau_events_visits.sql (simplified)
{{ config(materialized='table') }}
WITH period AS (
-- Rolling window: last 5 months to current
SELECT
YEAR(CURRENT_DATE - INTERVAL '5' MONTH) AS start_year,
MONTH(CURRENT_DATE - INTERVAL '5' MONTH) AS start_month,
YEAR(CURRENT_DATE) AS end_year,
MONTH(CURRENT_DATE) AS end_month
),
events AS (
-- Pull visit events within the period window
SELECT src._tenant, src.unmergedCustomerId,
'visits' AS src_type, src.endpoint
FROM {{ source('final', 'customerstracking_visits') }} src
CROSS JOIN period p
WHERE src.unmergedCustomerId IS NOT NULL
AND /* ...timestamp filtering by year/month bounds... */
),
events_with_customer AS (
-- Resolve merged customer IDs
SELECT e._tenant,
COALESCE(mc.mergedCustomerId, e.unmergedCustomerId) AS customerId,
e.src_type, e.endpoint
FROM events e
LEFT JOIN {{ ref('int_merged_customers') }} mc
ON e._tenant = mc._tenant
AND e.unmergedCustomerId = mc.unmergedCustomerId
)
-- Keep only actual (non-deleted) customers
SELECT ewc._tenant, ewc.customerId, ewc.src_type, ewc.endpoint
FROM events_with_customer ewc
WHERE EXISTS (
SELECT 1 FROM {{ ref('int_actual_customers') }} ac
WHERE ewc._tenant = ac._tenant
AND ewc.customerId = ac.customerId
)Les 10 sources d’événements suivent exactement le même modèle. Les seules différences sont la table source et les filtres. Ensuite, les modèles fusionnent en un seul flux :
-- int_mau_events.sql (union of all sources)
SELECT * FROM {{ ref('int_mau_events_inapps_targetings') }}
UNION ALL
SELECT * FROM {{ ref('int_mau_events_inapps_clicks') }}
UNION ALL
SELECT * FROM {{ ref('int_mau_events_visits') }}
UNION ALL
SELECT * FROM {{ ref('int_mau_events_orders') }}
-- ...plus 6 more sourcesEt enfin, le datamart où tout est agrégé :
-- mau_period_datamart.sql
{{ config(
materialized='incremental',
incremental_strategy='merge',
unique_key=['_tenant', 'start_year', 'start_month', 'end_year', 'end_month']
) }}
{%- set months_back = var('months_back', 5) | int -%}
WITH period AS (
SELECT
YEAR(CURRENT_DATE - INTERVAL '{{ months_back }}' MONTH) AS start_year,
MONTH(CURRENT_DATE - INTERVAL '{{ months_back }}' MONTH) AS start_month,
YEAR(CURRENT_DATE) AS end_year,
MONTH(CURRENT_DATE) AS end_month
),
events_resolved AS (
SELECT * FROM {{ ref('int_mau_events') }}
),
metrics_by_tenant AS (
SELECT
er._tenant,
COUNT(DISTINCT CASE WHEN src_type = 'visits'
THEN customerId END) AS CustomersTracking_Visits,
COUNT(DISTINCT CASE WHEN src_type = 'orders'
THEN customerId END) AS ProcessingOrders_Orders,
COUNT(DISTINCT CASE WHEN src_type = 'mailings'
THEN customerId END) AS Mailings_MessageStatuses,
-- ...other metrics
COUNT(DISTINCT customerId) AS MAU
FROM events_resolved er
GROUP BY er._tenant
)
SELECT m.*, p.start_year, p.start_month, p.end_year, p.end_month
FROM metrics_by_tenant m
CROSS JOIN period pPour la configuration du datamart, nous utilisons incremental_strategy='merge'. dbt génère automatiquement la requête de fusion, en remplaçant le unique_key pour l’insertion. Pas besoin d’implémenter manuellement un chargement incrémentiel.
Pour lier les modèles en un seul projet, nous avons mis en place dbt_project.yaml:
name: mau_period
version: '1.0.0'
models:
mau_period:
+on_table_exists: replace
+on_schema_change: append_new_columnsEt sources.yamlqui décrit les tables d’entrée :
sources:
- name: final
database: data_platform
schema: final
tables:
- name: inapps_targetings_v2
- name: inapps_clicks_v2
- name: customerstracking_visits
- name: processingorders_orders
- name: cdp_mergedcustomers_v2
# ...Le résultat est la même logique métier que celle que nous avions dans PySpark, mais en SQL pur : sources.yaml remplace les schémas typéspark, {{ ref() }} et {{ source() }} remplacer .get_table()et l’ordre d’exécution automatique via le graphe de dépendances remplace le réglage manuel des ressources Spark.
Comment nous configurons Airflow : dag.yaml
Le quatrième fichier de configuration définit quand et comment Airflow exécute le pipeline :
product: sg-team
feature: billing
schema: mau
schedule: "15 21 * * *" # every day at 00:15 MSK
params:
- name: start_date
description: "Start date (YYYY-MM-DD). Leave empty for auto"
default: ""
- name: end_date
description: "End date (YYYY-MM-DD). Leave empty for auto"
default: ""
- name: months_back
description: "Months to look back (default: 5)"
default: 5
alerts:
enabled: true
severity: warningEnsuite, notre script Python analyse dag.yaml et dbt_project.yaml et utilise la bibliothèque Cosmos pour générer un DAG Airflow entièrement fonctionnel. C’est le seul morceau de code Python dans toute la configuration. Il est écrit une fois et fonctionne pour chaque projet dbt. Voici la partie clé :
def _build_dbt_project_dags(project_path: Path, environ: dict) -> list[DbtDag]:
config_dict = yaml.safe_load(dag_config_path.read_text())
config = DagConfig.model_validate(config_dict)
# YAML params → Airflow Params
params = {}
operator_vars = {}
for param in config.params:
params[param.name] = Param(
default=param.default if param.default is not None else "",
description=param.description,
)
operator_vars[param.name] = f"{{{{ params.{param.name} }}}}"
# Cosmos creates the DAG from the dbt project
with DbtDag(
dag_id=f"dbt_{project_path.name}",
schedule=config.schedule,
params=params,
project_config=ProjectConfig(dbt_project_path=project_path),
profile_config=ProfileConfig(
profile_name="default",
target_name=project_name,
profile_mapping=TrinoLDAPProfileMapping(
conn_id="trino_default",
profile_args={
"database": profile_database,
"schema": profile_schema,
},
),
),
operator_args={"vars": operator_vars},
) as dag:
# Create schema before running models
create_schema = SQLExecuteQueryOperator(
task_id="create_schema",
conn_id="trino_default",
sql=f"CREATE SCHEMA IF NOT EXISTS {profile_database}.{profile_schema} ...",
)
# Attach to root tasks
for unique_id, _ in dag.dbt_graph.filtered_nodes.items():
task = dag.tasks_map[unique_id]
if not task.upstream_task_ids:
create_schema >> taskCosmos lit manifest.json à partir du projet dbt, analyse le graphique de dépendance du modèle et crée une tâche Airflow distincte pour chaque modèle. Les dépendances des tâches sont créées automatiquement en fonction de ref() appels dans le SQL.
Comment les analystes créent des pipelines sans développeurs
Désormais, lorsqu’un analyste a besoin d’un nouveau pipeline récurrent, il peut le mettre en place en quelques étapes :
Étape 1. Créez un dossier dans le dépôt : dbt-projects/my_new_pipeline/.
Étape 2. Si l’ingestion de données externes est nécessaire, écrivez une configuration YAML pour dlt.
Étape 3. Écrivez des modèles SQL dans le models/ dossier et décrire les sources dans sources.yaml.
Étape 4. Créer dbt_project.yaml et dag.yaml.
Étape 5. Poussez vers Git, passez en revue, fusionnez.
CI/CD crée le projet dbt et envoie les artefacts à S3. Airflow lit les fichiers DAG à partir de là, Cosmos analyse le projet dbt et génère le graphique des tâches. Dans les délais prévus, dbt exécute les modèles sur Trino dans le bon ordre. Le résultat final est un datamart mis à jour dans l’entrepôt, accessible via Superset.
Ce qui a changé après la migration

Pour que les analystes puissent créer eux-mêmes des pipelines, ils doivent comprendre ref() et source() concepts, la différence entre table et incremental la matérialisation et les bases de Git. Nous avons organisé quelques ateliers internes et élaboré des guides étape par étape pour chaque type de tâche.
Pourquoi la nouvelle pile ne remplace pas complètement PySpark
Pour environ 10 % de nos pipelines, PySpark reste la seule option, lorsqu’une transformation ne rentre tout simplement pas dans SQL. dbt prend en charge les macros Jinja, mais cela ne remplace pas Python à part entière. Et il serait malhonnête de passer outre les limites des nouveaux outils.
dlt + Delta : prise en charge expérimentale des upserts. Nous utilisons le format Delta dans notre couche de stockage. Le connecteur Delta de dlt est marqué comme expérimental, donc la stratégie de fusion n’a pas fonctionné immédiatement. Nous avons dû trouver des solutions de contournement — dans certains cas, nous avons utilisé replace au lieu de merge (en sacrifiant l’incrémentalité), et dans d’autres, nous avons écrit des processing_steps.
La tolérance aux pannes limitée de Trino. Trino dispose d’un mécanisme de tolérance aux pannes, mais il fonctionne en écrivant les résultats intermédiaires dans S3. Compte tenu de nos volumes de données à l’échelle du téraoctet, cela n’est pas pratique : le grand nombre d’opérations S3 rend ce coût prohibitif. Sans la tolérance aux pannes activée, si un travailleur Trino tombe en panne, la requête entière échoue. Spark, en revanche, redémarre uniquement la tâche ayant échoué. Nous avons résolu ce problème avec des tentatives au niveau DAG et en décomposant les modèles lourds en chaînes de modèles intermédiaires.
UDF et logique personnalisée. Dans Spark, vous pouvez écrire une logique personnalisée en Python directement dans le pipeline, ce qui est très pratique. Avec la nouvelle architecture, c’est beaucoup plus difficile. dbt au-dessus de Trino n’aide pas : Jinja génère uniquement du SQL et les modèles Python de dbt ne fonctionnent qu’avec Snowflake, Databricks et BigQuery. Vous pouvez écrire des UDF dans Trino, mais uniquement en Java – avec toute la surcharge que cela implique : un dépôt séparé, un pipeline de construction, le déploiement de JAR sur tous les travailleurs. Ainsi, lorsqu’une transformation ne rentre pas dans SQL, vous vous retrouvez soit avec un monstre SQL impossible à maintenir, soit avec un script autonome qui rompt le lignage.
Et ensuite : tests, modèles de modèles et formation
De meilleurs tests. Nous avons effectué des tests de pipeline solides dans PySpark, mais la nouvelle architecture est toujours en train de rattraper son retard. Les versions récentes de dbt ont introduit les tests unitaires : vous pouvez désormais valider la logique du modèle SQL par rapport à des données fictives sans lancer le pipeline complet. Nous souhaitons ajouter des tests dbt à la fois au niveau du modèle et en tant que couche de surveillance distincte.
Modèles réutilisables pour les modèles courants. Beaucoup de nos modèles de dette se ressemblent. Une seule configuration peut décrire une douzaine de modèles avec le même modèle : seuls la table source et les filtres diffèrent. Nous prévoyons d’extraire la logique partagée dans les macros dbt.
Élargir la base d’utilisateurs de la plateforme. Nous souhaitons que davantage d’ingénieurs et d’analystes travaillent avec les données de manière indépendante. Nous prévoyons des sessions de formation internes régulières, de la documentation et des guides d’intégration afin que les nouveaux utilisateurs puissent se mettre rapidement au courant et commencer à créer leurs propres modèles.
Si votre équipe est coincée dans la même boucle « les analystes attendent les développeurs », j’aimerais savoir comment vous le résolvez. Connectez-vous avec moi sur LinkedIn et comparons nos notes.
Toutes les images de cet article sont de l’auteur, sauf indication contraire.


