
Introduction aux agents d’apprentissage par renforcement avec le moteur de jeu Unity
L’apprentissage par renforcement – apprendre à partir d’observations et de récompenses – est la méthode la plus proche de la façon dont les humains (et les animaux) apprennent.
Malgré cette similitude, cela reste également le domaine le plus compliqué et le plus ennuyeux de l’apprentissage automatique moderne. Pour citer le célèbre Andej Karpathy :
L’apprentissage par renforcement est terrible. Il se trouve que tout ce que nous avions avant était bien pire.
Pour aider à comprendre la méthode, je vais construire un exemple étape par étape d’un agent apprenant à naviguer dans un environnement à l’aide de Q-Learning. Le texte commencera par les premiers principes et se terminera par un exemple entièrement fonctionnel que vous pouvez exécuter dans le moteur de jeu Unity.
Pour cet article, une connaissance de base du langage de programmation C# est requise. Si vous n’êtes pas familier avec le moteur de jeu Unity, considérez simplement que chaque objet est un agent, qui :
- exécute
Start()une fois au début du programme, - et
Update()continuellement en parallèle avec les autres agents.
Le référentiel qui accompagne cet article est sur GitHub.
Qu’est-ce que l’apprentissage par renforcement
Dans l’apprentissage par renforcement (RL), nous avons un agent capable d’entreprendre des actions, d’observer les résultats de ces actions et d’apprendre des récompenses/punitions pour ces actions.

La façon dont un agent décide d’une action dans un certain état dépend de son politique. Une politique π est une fonction qui définit le comportement d’un agent, mappant les états aux actions. Étant donné un ensemble d’états S et un ensemble d’actions A une politique est un mappage direct : π: S → A .
De plus, si nous voulons que l’agent ait plus d’options possibles, avec un choix, nous pouvons créer un politique stochastique. Ensuite, plutôt qu’une action unique, une politique détermine la probabilité d’entreprendre chaque action dans un état donné : π: S × A → [0, 1].
Exemple de robot de navigation
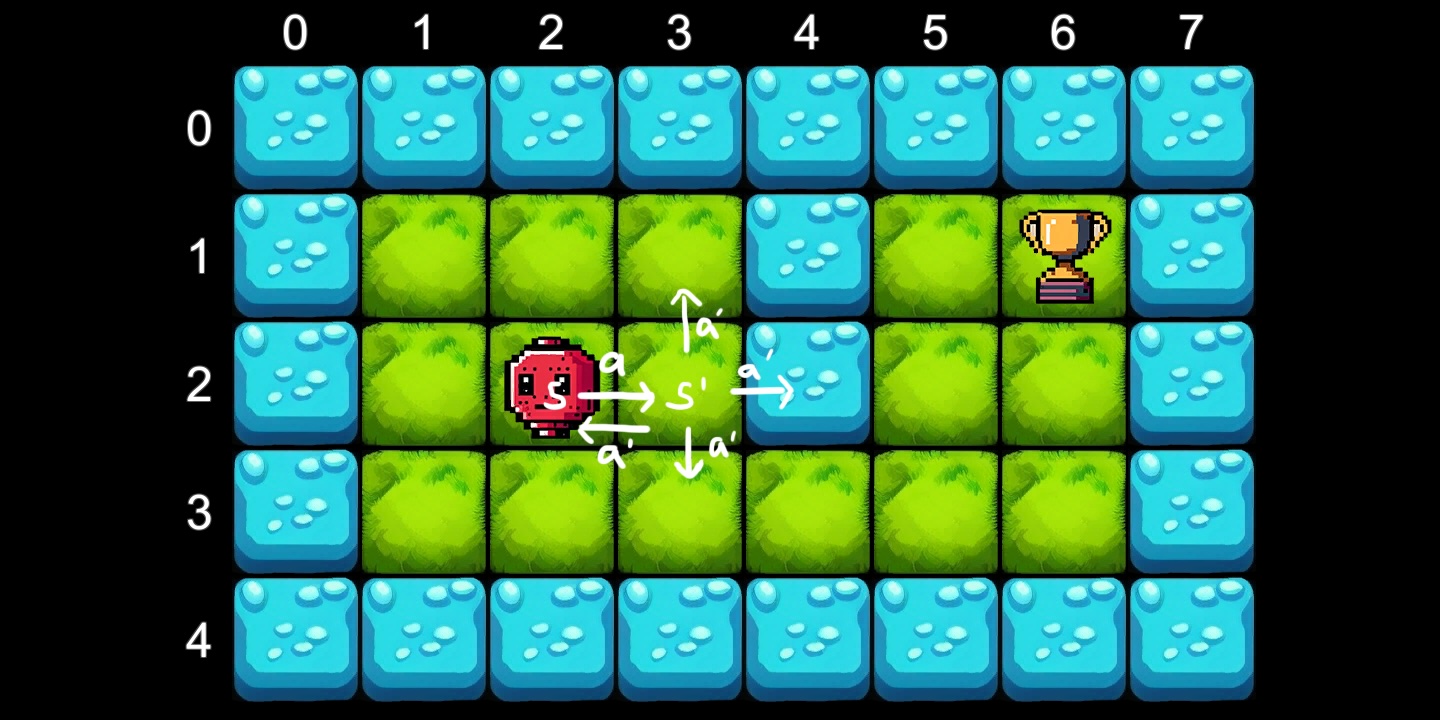
Pour illustrer le processus d’apprentissage, nous allons créer un exemple de robot de navigation dans un environnement 2D, en utilisant l’une des quatre actions suivantes, A = {Left, Right, Up, Down} . Le robot doit trouver le chemin vers la récompense à tout moment sur la carte, sans tomber dans l’eau.

Les récompenses seront codées avec les types de tuiles à l’aide d’un Enum :
public enum TileEnum { Water = -1, Grass = 0, Award = 1 }L’état est donné par sa position sur la grille, ce qui signifie que nous avons 40 états possibles : S = [0…7] × [0…4] (une grille de tuiles 8 × 5), que nous encodons à l’aide d’un tableau 2D :
_map = {
{ -1, -1, -1, -1, -1, -1, -1, -1 }, // all water border
{ -1, 0, 0, 0, -1, 0, 1, -1 }, // 1 = Award (trophy)
{ -1, 0, 0, 0, -1, 0, 0, -1 },
{ -1, 0, 0, 0, 0, 0, 0, -1 },
{ -1, -1, -1, -1, -1, -1, -1, -1 }, // all water border
}Nous stockons la carte dans une tuile TileGrid qui a les fonctions utilitaires suivantes :
// Obtain a tile at a coordinate
public T GetTileByCoords<T>(int x, int y);
// Given a tile and an action, obtain the next tile
public T GetTargetTile<T>(T source, ActionEnum action);
// Create a tile grid from the map
public void GenerateTiles();Nous utiliserons différents types de tuiles, d’où le générique T. Chaque tuile a un TileType donné par le TileEnum et donc aussi sa récompense qui peut être obtenue comme (int) TileType.
L’équation de Bellman
Le problème de trouver une politique optimale peut être résolu de manière itérative en utilisant la Équation de Bellman. L’équation de Bellman postule que la récompense à long terme d’une action est égale à la récompense immédiate de cette action. plus la récompense attendue de toutes les actions futures.
Il peut être calculé de manière itérative pour des systèmes avec des états discrets et des transitions d’état discrètes. Avoir:
s— l’état actuel,A— ensemble de toutes les actions,s'— état atteint en agissantaen états,γ— facteur d’actualisation (plus la récompense est élevée, moins sa valeur),R(s, a)— récompense immédiate pour avoir agiaen états
L’équation de Bellman indique alors que la valeur V(s) d’un état s est:

Résoudre l’équation de Bellman de manière itérative
Le calcul de l’équation de Bellman est un problème de programmation dynamique. A chaque itération nnous calculons la récompense future attendue accessible dans n+1 étapes pour toutes les tuiles. Pour chaque tuile, nous stockons cela à l’aide d’un Value variable.
On donne une base de récompense sur la tuile cible, c’est à dire 1 si le prix est atteint, -1 dans le robot tombe dans l’eau, et 0 sinon. Une fois que la récompense ou l’eau sont atteintes, aucune action n’est possible, donc la valeur de l’état reste à la valeur initiale. 0 .
Nous créons un gestionnaire qui va générer la grille et calculer les itérations :
private void Start()
{
tileGrid.GenerateTiles();
}
private void Update()
{
CalculateValues();
Step();
}Pour garder une trace des valeurs, nous utiliserons un VTile classe qui détient un Value. Pour éviter de prendre directement les valeurs mises à jour, nous définissons d’abord le NextValue puis définissez toutes les valeurs en même temps dans le Step() fonction.
private float gamma = 0.9; // Discounting factor
// The Bellman equation
private double GetNewValue(VTile tile)
{
return Agent.Actions
.Select(a => tileGrid.GetTargetTile(tile, a))
.Select(t => t.Reward + gamma * t.Value) // Reward in [1, 0, -1]
.Max();
}
// Get next values for all tiles
private void CalculateValues()
{
for (var y = 0; y < TileGrid.BOARD_HEIGHT; y++)
{
for (var x = 0; x < TileGrid.BOARD_WIDTH; x++)
{
var tile = tileGrid.GetTileByCoords<VTile>(x, y);
if (tile.TileType == TileEnum.Grass)
{
tile.NextValue = GetNewValue(tile);
}
}
}
}
// Copy next values to current values (iteration step)
private void Step()
{
for (var y = 0; y < TileGrid.BOARD_HEIGHT; y++)
{
for (var x = 0; x < TileGrid.BOARD_WIDTH; x++)
{
tileGrid.GetTileByCoords<VTile>(x, y).Step();
}
}
}À chaque étape, la valeur V(s) de chaque tuile est mis à jour au maximum sur toutes les actions de la récompense immédiate plus la valeur actualisée de la tuile résultante. La future récompense se propage vers l’extérieur de la tuile Récompense avec un rendement décroissant contrôlé par γ = 0.9 .

Qualité de l’action (valeurs Q)
Nous avons trouvé un moyen d’associer des états à des valeurs, ce qui est suffisant pour ce problème d’orientation. Cependant, cela se concentre sur l’environnement, ignorant l’agent. Pour un agent, nous voulons généralement savoir ce qui serait une bonne action dans l’environnement.
En Q-learning, cette valeur d’une action est appelée sa qualité (Valeur Q). Chaque (state, action) La paire se voit attribuer une seule valeur Q.

Où le nouvel hyperparamètre α définit un taux d’apprentissage – la rapidité avec laquelle les nouvelles informations remplacent les anciennes. Ceci est analogue à l’apprentissage automatique standard et les valeurs sont généralement similaires, nous utilisons ici 0.005 . Nous calculons ensuite le bénéfice d’une action en utilisant la différence temporelle D(s,a):

Puisque nous ne considérons plus toutes les actions dans l’état actuel, mais la qualité de chaque action séparément, nous ne maximisons pas toutes les actions possibles dans l’état actuel, mais plutôt toutes les actions possibles dans l’état que nous atteindrons après avoir entrepris l’action dont nous calculons la qualité, combinée avec la récompense pour avoir entrepris cette action.

Le terme de différence temporelle combine la récompense immédiate avec la meilleure récompense future possible, ce qui en fait une dérivation directe de l’équation de Bellman (voir Wiki pour plus de détails).
Pour former l’agent, nous instancions à nouveau une grille, mais cette fois nous créons également une instance de l’agent, placée à (2,2).
private Agent _agent;
private void ResetAgentPos()
{
_agent.State = tileGrid.GetTileByCoords<QTile>(2, 2);
}
private void Start()
{
tileGrid.GenerateTiles();
_agent = Instantiate(agentPrefab, transform);
ResetAgentPos();
}
private void Update()
{
Step();
}Un Agent l’objet a un état actuel QState. Chaque QStateconserve la valeur Q pour chaque action disponible. A chaque étape, l’agent met à jour la qualité de chaque action disponible dans l’état :
private void Step()
{
if (_agent.State.TileType != TileEnum.Grass)
{
ResetAgentPos();
}
else
{
QTile s = _agent.State;
// Update Q-values for ALL actions from current state
foreach (var a in Agent.Actions)
{
double q = s.GetQValue(a);
QTile sPrime = tileGrid.GetTargetTile(s, a);
double r = sPrime.Reward;
double qMax = Agent.Actions.Select(sPrime.GetQValue).Max();
double td = r + gamma * qMax - q;
s.SetQValue(a, q + alpha * td);
}
// Take the best available action a
ActionEnum chosen = PickAction(s);
_agent.State = tileGrid.GetTargetTile(s, chosen);
}
}Un Agent dispose d’un ensemble d’actions possibles dans chaque État et prendra la meilleure action dans chaque État.
S’il y a plusieurs meilleures actions, l’une d’entre elles est prise au hasard car nous avons mélangé les actions au préalable. En raison de ce caractère aléatoire, chaque entraînement se déroulera différemment, mais se stabilisera généralement entre 500 et 1 000 étapes.
C’est la base du Q-Learning. Contrairement au valeurs d’étatle qualité des actions peut être appliqué dans les situations où :
- l’observation est incomplète à un moment donné (champ de vision de l’agent)
- l’observation change (les objets bougent dans l’environnement)
Exploration vs Exploitation (ε-Greedy)
Jusqu’à présent, l’agent a pris la meilleure action possible à chaque fois, mais cela peut l’amener à se retrouver rapidement bloqué dans un optimum local. Un défi clé du Q-Learning est le compromis exploration-exploitation :
- Exploiter : choisissez l’action avec la valeur Q connue la plus élevée (gourmande).
- Explorez : choisissez une action aléatoire pour découvrir des chemins potentiellement meilleurs.
Politique ε-Gourde
Étant donné une valeur aléatoire r ∈ [0, 1] et paramètre epsilon il y a deux options :
- si
r > epsilonpuis sélectionnez la meilleure action (exploiter), - sinon sélectionnez une action aléatoire (explorer).
Epsilon en décomposition
Nous souhaitons généralement explorer davantage dès le début et exploiter davantage plus tard. Ceci est réalisé en décomposant epsilon au fil du temps:
epsilon = max(epsilonMin, epsilon − epsilonDecay)Après suffisamment d’étapes, la politique de l’agent converge presque toujours vers la sélection de l’action de qualité maximale.
private epsilonMin = 0.05;
private epsilonDecay = 0.005;
private ActionEnum PickAction(QTile state) {
ActionEnum action = Random.Range(0f, 1f) > epsilon
? Agent.Actions.Shuffle().OrderBy(state.GetQValue).Last() // exploit
: Agent.RndAction(); // explore
epsilon = Mathf.Max(epsilonMin, epsilon - epsilonDecay);
return action;
}L’écosystème RL plus large
Q-Learning est un algorithme au sein d’une plus grande famille de méthodes d’apprentissage par renforcement (RL). Les algorithmes peuvent être classés selon plusieurs axes :
- Espace d’état : Discret (par exemple, jeux de société) | Continu (par exemple, jeux FPS)
- Espace Actions : Discret (par exemple, jeux de stratégie) | Continu (par exemple, conduite)
- Type de politique : Hors politique (Q-Learning :
a’est toujours maximisé) | Conformément à la politique (SARSA :a’est sélectionné par la politique actuelle de l’agent) - Opérateur: Valeur | Qualité | Avantage
A(s, a) = Q(s, a) − V(s)
Pour une liste complète des algorithmes RL, voir le Page Wikipédia sur l’apprentissage par renforcement. Des méthodes supplémentaires telles que le clonage comportemental n’y sont pas répertoriées mais sont également utilisées dans la pratique. Les solutions du monde réel utilisent généralement des variantes étendues ou des combinaisons de ce qui précède.
Q-Learning est une méthode à action discrète hors politique. L’étendre à des espaces d’état/d’action continus conduit à des méthodes telles que Deep Q-Networks (DQN), qui remplacent la Q-table par un réseau neuronal.
Dans l’exemple du monde en grille, la Q-table a |S| × |A| = 40 × 4 = 160 entrées – parfaitement gérables. Mais pour un jeu comme les échecs, l’espace d’état dépasse 10⁴⁴ positions, rendant un tableau explicite impossible à stocker ou à remplir. Dans de tels cas, des réseaux de neurones peuvent être utilisés pour compresser les informations.

(s, a) paire, le réseau prend l’état comme entrée et génère des valeurs Q pour toutes les actions, généralisant à des états similaires qu’il n’a jamais vus auparavant.You may also like


