
Tous les problèmes RecSys ne sont pas créés égaux
Les valeurs aberrantes de l’industrie ont déformé notre définition des systèmes de recommandation. TikTok, Spotify et Netflix utilisez des modèles hybrides d’apprentissage profond combinant un filtrage collaboratif et basé sur le contenu pour fournir des recommandations personnalisées que vous ne saviez même pas que vous aimeriez. Si vous envisagez un rôle RecSys, vous pouvez vous attendre à vous y plonger immédiatement. Mais tous les problèmes RecSys ne fonctionnent pas – ou ne doivent pas fonctionner – à ce niveau. La plupart des praticiens travaillent avec des modèles tabulaires relativement simples, souvent des arbres à gradient amélioré. Jusqu’à ce que je participe au RecSys ’25 à Prague, je pensais que mon expérience était aberrante. Aujourd’hui, je crois que c’est la norme, cachée derrière les énormes valeurs aberrantes qui déterminent l’état de l’art de l’industrie. Alors, qu’est-ce qui distingue ces géants de la plupart des autres entreprises ? Dans cet article, j’utilise le cadre cartographié dans l’image ci-dessus pour raisonner sur ces différences et vous aider à placer votre propre travail de recommandation sur le spectre.
La plupart des systèmes de recommandation commencent par un génération de candidats phase, réduisant des millions d’éléments possibles à un ensemble gérable qui peut être reclassé par des solutions à latence plus élevée. Mais la génération de candidats ce n’est pas toujours la bataille difficile qu’on prétend êtreet cela ne nécessite pas nécessairement d’apprentissage automatique. Les contextes avec des portées bien définies et des filtres stricts ne nécessitent souvent pas de logique d’interrogation complexe ou de recherche vectorielle. Considérer Réservation.com: lorsqu’un utilisateur recherche « hôtels 4 étoiles à Barcelone, du 12 au 15 septembre », les contraintes géographiques et de disponibilité ont déjà réduit des millions de propriétés à quelques centaines, même si les systèmes backend gérant ce filtrage sont eux-mêmes complexes. Le véritable défi pour les praticiens du machine learning est alors de classer ces hôtels avec précision. C’est très différent de Recherche de produits Amazon ou le Page d’accueil YouTubeoù les filtres durs sont absents. Dans ces environnements, le système doit s’appuyer sur l’intention sémantique ou le comportement passé pour faire apparaître les candidats pertinents parmi des millions ou des milliards d’éléments avant même que le reclassement ait lieu.
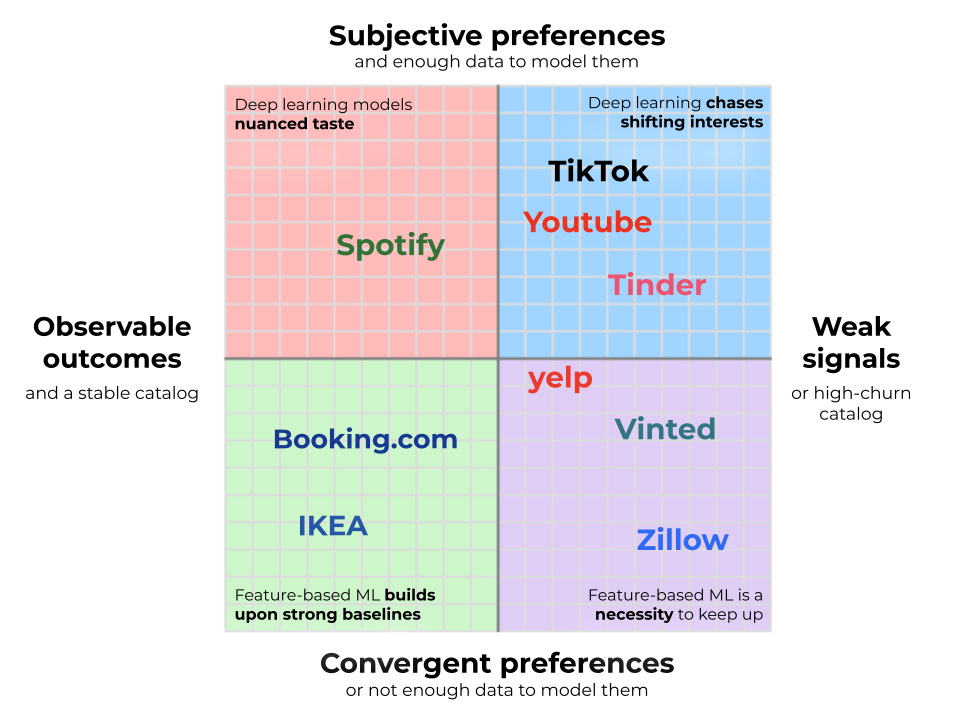
Au-delà de la génération de candidats, la complexité de reclassement est mieux compris à travers les deux dimensions cartographiées dans l’image ci-dessous. D’abord, résultats observables et stabilité du cataloguequi détermine la force de votre base de référence. Deuxièmement, le subjectivité des préférences et leur capacité d’apprentissage, qui détermine la complexité de votre solution de personnalisation.

Résultats observables et stabilité du catalogue
À l’extrémité gauche de l’axe des X se trouvent les entreprises qui observent directement leurs résultats les plus importants. Les grands commerçants aiment IKEA en sont un bon exemple : lorsqu’un client achète un canapé ESKILSTUNA au lieu d’un KIVIK, le signal est sans ambiguïté. Regroupez-en suffisamment et l’entreprise sait exactement quel produit a le taux d’achat le plus élevé. Lorsque vous pouvez observer directement les utilisateurs voter avec leur portefeuille, vous disposez d’une base de référence solide, difficile à battre..
À l’autre extrême se trouvent les plateformes qui ne peuvent pas vérifier si leurs recommandations ont réellement abouti. Tinder et Bourdon peuvent voir les utilisateurs correspondre, mais ils ne sauront souvent pas si la paire s’est bien entendue (surtout lorsque les utilisateurs se déplacent vers d’autres plates-formes). Japper et Google Cartes peuvent recommander des restaurants, mais pour la grande majorité, ils ne peuvent pas savoir si vous avez réellement visité, mais simplement sur quelles listes vous avez cliqué. S’appuyer sur de tels signaux du haut de l’entonnoir signifie biais de position domine : les éléments en première position accumulent des interactions quelle que soit leur véritable qualité, ce qui rend presque impossible de déterminer si l’engagement reflète une véritable préférence ou une simple visibilité. Comparez cela avec l’exemple IKEA : un utilisateur peut cliquer sur un restaurant sur Yelp simplement parce qu’il apparaît en premier, mais il est beaucoup moins susceptible d’acheter un canapé pour la même raison. En l’absence d’une conversion concrète, vous perdez l’ancre d’un classement fiable. Cela vous oblige à travailler beaucoup plus dur pour extraire le signal du bruit. Les critiques peuvent offrir une certaine base, mais elles sont rarement suffisamment denses pour servir de signal principal. Au lieu de cela, il vous reste à effectuez des expériences sans fin sur vos heuristiques de classement, en ajustant constamment la logique pour extraire un proxy de qualité à partir d’un flux de signaux faibles.
Catalogue à fort taux de désabonnement
Toutefois, même avec des résultats observables, une base de référence solide n’est pas garantie. Si votre catalogue évolue constamment, vous risquez de ne pas accumuler suffisamment de données pour créer un classement approprié.. Des plateformes immobilières comme Zillow et des sites d’occasion comme Vinté face à la version la plus extrême : chaque article a un inventaire d’un, disparaissant au moment de son achat. Cela vous oblige à vous fier à des tris simplistes et rigides comme « le plus récent en premier » ou « le prix le plus bas au mètre carré ». Ceux-ci sont bien plus faibles que les classements de conversion basés sur un signal utilisateur réel et dense. Pour faire mieux, vous devez tirer parti du machine learning pour prédire immédiatement la probabilité de conversion, en combinant les attributs intrinsèques avec des performances à court terme biaisées pour faire apparaître le meilleur inventaire avant qu’il ne disparaisse.
L’omniprésence des modèles basés sur les fonctionnalités
Quelle que soit la stabilité de votre catalogue ou la force du signal, le principal défi reste le même : vous essayez d’améliorer la base de référence disponible. Ceci est généralement réalisé en entraînant un modèle d’apprentissage automatique (ML) pour prédire la probabilité d’engagement ou de conversion dans un contexte spécifique. Les arbres boostés par gradient (GBDT) sont le choix pragmatique, beaucoup plus rapides à former et à régler que l’apprentissage en profondeur.
Les GBDT prédisent ces résultats sur la base des caractéristiques des articles fabriqués : des attributs catégoriels et numériques qui quantifient et décrivent un produit. Avant même que les préférences individuelles ne soient connues, les GBDT peuvent également adapter les recommandations en tirant parti des fonctionnalités de base de l’utilisateur telles que le pays et le type d’appareil. Avec ces seules fonctionnalités d’article et d’utilisateur, un modèle ML peut déjà améliorer la référence, qu’il s’agisse de débiguer un classement de popularité ou de classer un flux à fort taux de désabonnement. Par exemple, dans le commerce électronique de mode, les mannequins utilisent généralement le lieu et la période de l’année pour présenter les articles liés à la saison, tout en utilisant simultanément le pays et l’appareil pour calibrer le prix.
Ces fonctionnalités permettent au modèle de lutter contre le biais de position susmentionné en séparant la véritable qualité de la simple visibilité. En apprenant quels attributs intrinsèques conduisent à la conversion, le modèle peut corriger le biais de position inhérent à votre base de popularité. Il apprend à identifier les éléments qui fonctionnent selon leur mérite, plutôt que simplement parce qu’ils ont été classés en tête. C’est plus difficile qu’il n’y paraît : vous risquez de rétrograder les gagnants confirmés plus que vous ne le devriez, ce qui pourrait dégrader l’expérience.
Contrairement à la croyance populaire, les modèles basés sur les fonctionnalités peuvent également favoriser la personnalisationen fonction de la quantité d’informations sémantiques que contiennent naturellement les éléments. Des plateformes comme Réservation.com et Japper accumulez des descriptions riches, plusieurs photos et des avis d’utilisateurs qui fournissent une profondeur sémantique par annonce. Ceux-ci peuvent être codés dans des intégrations sémantiques à des fins de personnalisation : en utilisant les interactions récentes de l’utilisateur, nous pouvons calculer des scores de similarité par rapport aux éléments candidats et les transmettre au modèle amélioré par gradient en tant que fonctionnalités.
Cette approche a cependant ses limites. Les modèles basés sur les fonctionnalités peuvent recommander en fonction de la similitude avec les interactions récentes, mais contrairement au filtrage collaboratif, ils n’apprennent pas directement quels éléments ont tendance à être appréciés par les utilisateurs similaires.. Pour apprendre cela, ils ont besoin de scores de similarité d’éléments fournis en tant que fonctionnalités d’entrée. L’importance de cette limitation dépend de quelque chose de plus fondamental : le degré de désaccord réel des utilisateurs.
Subjectivité
Tous les domaines ne sont pas également personnels ou controversés. Dans certains cas, les utilisateurs s’accordent largement sur ce qui constitue un bon produit une fois les contraintes de base satisfaites. Nous appelons ces préférences convergentes et elles occupent la moitié inférieure du graphique. Prendre Réservation.com: les voyageurs peuvent avoir des budgets et des préférences de localisation différents, mais une fois ceux-ci révélés grâce aux filtres et aux interactions cartographiques, les critères de classement convergent : des prix plus élevés sont mauvais, les équipements sont bons, les bonnes critiques sont meilleures. Ou considérez Agrafes: une fois qu’un utilisateur a besoin de papier d’imprimante ou de piles AA, la marque et le prix dominent, ce qui rend les préférences de l’utilisateur remarquablement cohérentes.
À l’autre extrême – la moitié supérieure – se trouvent des domaines subjectifs définis par des goûts très fragmentés. Spotify illustre ceci : la piste préférée d’un utilisateur est le saut immédiat d’un autre. Pourtant, le goût existe rarement en vase clos. Quelque part dans les données se trouve un utilisateur sur votre longueur d’onde exacte, et l’apprentissage automatique comble le fossé, transformant leurs découvertes d’hier en recommandations d’aujourd’hui. Ici, la valeur de la personnalisation est énorme, tout comme l’investissement technique requis.
Les bonnes données
Le goût subjectif n’est exploitable que si vous disposez de suffisamment de données pour l’observer. De nombreux domaines impliquent des préférences distinctes mais ne disposent pas de la boucle de rétroaction permettant de les capturer. Une plateforme de contenu de niche, une nouvelle place de marché ou un produit B2B peuvent être confrontés à des goûts extrêmement divergents sans toutefois recevoir le signal clair pour les apprendre. Japper les recommandations de restaurants illustrent ce défi : les préférences culinaires sont subjectives, mais la plateforme ne peut pas observer les visites réelles au restaurant, seulement les clics. Cela signifie qu’ils ne peuvent pas optimiser la personnalisation pour la véritable cible (conversions). Ils ne peuvent optimiser que les mesures proxy telles que les clics, mais un nombre accru de clics peut en fait signaler un échec, indiquant que les utilisateurs parcourent plusieurs listes sans trouver ce qu’ils veulent.
Mais dans les domaines subjectifs où les données comportementales sont denses, le manque de personnalisation laisse de l’argent sur la table. YouTube en est un exemple : avec des milliards d’interactions quotidiennes, la plate-forme apprend les préférences nuancées des spectateurs et présente des vidéos dont vous ne saviez pas que vous vouliez. Ici, l’apprentissage profond devient incontournable. C’est à ce moment-là que vous verrez de grandes équipes se coordonner sur les factures Jira et cloud qui nécessitent l’approbation du vice-président. La justification de cette complexité dépend entièrement des données dont vous disposez.
Sachez où vous en êtes
Comprendre où se situe votre problème sur ce spectre est bien plus précieux que de rechercher aveuglément la dernière architecture. L’« état de l’art » du secteur est largement défini par les valeurs aberrantes : les géants de la technologie qui gèrent des inventaires massifs et subjectifs et des données utilisateur denses. Leurs solutions sont célèbres parce que leurs problèmes sont extrêmes, et non parce qu’elles sont universellement correctes.
Cependant, vous serez probablement confronté à différentes contraintes dans votre propre travail. Si votre domaine est défini par un catalogue stable et des résultats observables, vous atterrissez dans le quadrant inférieur gauche aux côtés d’entreprises comme IKEA et Réservation.com. Ici, les bases de popularité sont si solides que le défi consiste simplement à s’appuyer sur elles avec des modèles d’apprentissage automatique capables de générer des victoires mesurables aux tests A/B. Si, au contraire, vous faites face à un taux de désabonnement élevé (comme Vinté) ou des signaux faibles (comme Japper), l’apprentissage automatique devient une nécessité pour suivre le rythme.
Mais cela ne veut pas dire que vous aurez besoin apprentissage profond. Cette complexité supplémentaire n’est vraiment payante que dans les territoires où les préférences sont profondément subjectives et où il existe suffisamment de données pour les modéliser. Nous traitons souvent des systèmes comme Netflix ou Spotify comme la référence, mais ce sont des solutions spécialisées pour des conditions rares. Pour le reste d’entre nous, l’excellence ne consiste pas à déployer l’architecture la plus complexe disponible ; il s’agit de reconnaître les contraintes du terrain et d’avoir la confiance nécessaire pour choisir la solution qui résout vos problèmes.
Images de l’auteur.


