

La proximité du score initial comme critère d’évaluation
Introduction
Ces dernières années, les réseaux contradictoires génératifs (GAN) ont obtenu des résultats remarquables en matière de synthèse automatique d’images. Cependant, évaluer objectivement la qualité des données générées reste un défi ouvert. Contrairement aux modèles discriminants, pour lesquels des métriques établies existent, les modèles génératifs nécessitent des critères d’évaluation capables de mesurer à la fois l’impact visuel qualité et diversité des échantillons produits.
L’une des premières mesures utilisées a été le score initial (IS). Basé sur les prédictions d’un réseau Inception pré-entraîné, l’Inception Score fournit une estimation quantitative de la capacité d’un modèle génératif à produire des images réalistes et sémantiquement significatives.
Dans cet article, nous analysons l’idée derrière ce paramètre et une manière de comprendre sa validité, en analysant les limites qui ont conduit à l’utilisation d’autres mesures d’évaluation.
1. Qu’est-ce qu’un réseau adverse génératif (GAN)
Le réseau peut être défini comme un framework de Deep Learning qui, étant donné une distribution initiale de données (Training Set), permet de générer de nouvelles données (données synthétiques) avec des fonctionnalités similaires à la distribution initiale.
Habituellement, pour abstraire le concept de GAN, on peut se référer à la métaphore du « faussaire et critique d’art ». Le faussaire (Générateur) vise à peindre des images (données synthétiques) aussi proches que possible des images authentiques (Ensemble d’entraînement). En revanche, le critique d’art (Discriminator) vise à distinguer quels tableaux sont peints par le faussaire et lesquels sont authentiques. Comme vous pouvez l’imaginer, le but ultime du faussaire est de tromper le critique d’art, ou plutôt de peindre des tableaux que le critique d’art reconnaîtra comme authentiques.
Au début, le faussaire ne sait pas tromper le critique, il lui sera donc relativement facile de reconnaître les contrefaçons. Mais petit à petit, grâce aux retours des critiques, le faussaire saura comprendre ses erreurs et s’améliorer, jusqu’à atteindre son objectif.
Traduisant cette métaphore en termes pratiques, un GAN se compose de deux agents :

- Générateur (G): est responsable de reproduction données synthétiques. Il reçoit un vecteur de bruit z comme entrée, généralement tirée d’une distribution normale N(0,1) avec une moyenne de 0 et une variance de 1. Ce vecteur passera par le générateur, qui renverra une « image générée ». La forme de l’entonnoir du générateur n’est pas aléatoire. En fait, G effectue une suréchantillonnage processus : supposons que z ait une taille [1,300]; au fur et à mesure qu’il traverse les différentes couches du générateur, sa taille augmente jusqu’à devenir une image dimensionnée [64,64,3].
- Discriminateur (D) : discrimine ou plutôt classe quelles données appartiennent à la distribution réelle et lesquelles sont des données synthétiques. Contrairement au Générateur, le discriminateur effectue une sous-échantillonnage processus: supposons que l’image d’entrée a des dimensions [64,64,3]; le discriminateur extraira des caractéristiques telles que les bords, les couleurs, etc., jusqu’à ce qu’il renvoie une valeur de 0 (fausse image) ou 1 (image réelle)
Le z Le vecteur joue un rôle important. En fait, une propriété du générateur est qu’il produit des images présentant des caractéristiques différentes. Autrement dit, nous ne souhaitons pas que G produise toujours le même tableau ou des tableaux similaires (mode effondrement).
Pour y parvenir, j’ai besoin de mon vecteur z avoir des valeurs différentes. Ceux-ci activeront les poids du générateur différemment, produisant différentes caractéristiques de sortie.
2. Score initial (IS)
L’œil humain est sans aucun doute l’une des meilleures « mesures » pour évaluer un réseau GAN. Mais… quels paramètres utilisons-nous pour évaluer un réseau génératif ? Les paramètres importants sont certainement les qualité et diversité des images générées : (i) La qualité fait référence à comme c’est bon une image. Par exemple, si nous avons entraîné notre générateur à produire des images de chiens, l’œil humain doit effectivement reconnaître la présence d’un chien dans l’image produite. (ii) La diversité fait référence à la capacité du réseau à produire des images différentes. Poursuivant notre exemple, les chiens doivent être représentés dans des environnements différents, avec des races et des poses différentes.
Évidemment, évaluer « à la main » toutes les images possibles produites par un générateur devient difficile. L’Inception Score (IS) nous vient en aide. L’IS est une métrique utilisée pour déterminer la qualité d’un réseau GAN dans la génération d’images. Son nom dérive de l’utilisation du réseau de classification Inception développé par Google et pré-entraîné sur l’ensemble de données ImageNet (1000 classes). En particulier, le SI considère à la fois les propriétés de qualité et de diversité évoquées ci-dessus, à travers deux types de probabilité. Les deux distributions de probabilité sont obtenues en considérant un lot d’environ 50 000 images générées et les résultats de la dernière couche de classification du réseau.
- Probabilité conditionnelle (Pc) : La probabilité conditionnelle fait référence à la capacité de G à générer des images avec des sujets bien définis, c’est-à-dire à la qualité de l’image. Les images sont classées comme appartenant fortement à une classe spécifique. Ici, l’entropie est faible (faible effet de surprise), ou plutôt la distribution des classifications est concentrée sur une seule classe. Les dimensions du PC sont [batch,1000].
- Probabilité marginale (Pm) : La probabilité marginale permet de comprendre si le générateur est capable de générer des images avec des caractéristiques différentes. Si ce n’était pas le cas, nous pourrions avoir un symptôme de mode effondrementc’est-à-dire que le générateur produit toujours des images identiques les unes aux autres. La probabilité marginale est obtenue en considérant ordinateur et calculer la moyenne sur l’axe 0 (pour lequel on calcule la moyenne sur le lot). Dans ce cas, la distribution de classification doit être une distribution uniforme. Les dimensions de PM sont [1,1000].
Un exemple de ce qui a été expliqué est montré dans l’image.

La dernière étape consiste à combiner les deux probabilités. Cette phase est réalisée en calculant la distance KL (Kullback – Leibler) entre Pc et Pm et en faisant la moyenne sur le nombre d’exemples utilisés. En d’autres termes, en considérant le i-ème vecteur de Pc, on voit à quel point la probabilité conditionnelle de la i-ème image s’écarte de la moyenne.
Le résultat souhaité est que cette distance soit élevée. En fait:
- En supposant que le générateur produit des images cohérentes, alors, pour chaque image, la probabilité conditionnelle est concentrée sur une seule classe.
- Si le générateur ne présente pas d’effondrement de mode, alors les images sont classées en différentes classes.
Et là une question se pose : Élevé par rapport à quoi ?
3. Voisinage des données synthétiques
Soit ISᵣₑₐₗ le score initial calculé sur l’ensemble de données de test et ISₛ celui calculé sur les données générées. Un modèle génératif peut être considéré comme satisfaisant lorsque :
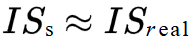
ou mieux lorsque le score initial des données synthétiques est proche de celui des données réelles, ce qui suggère que le modèle reproduit correctement la distribution des étiquettes et la complexité visuelle de l’ensemble de données d’origine.
3.1. Limites
L’introduction du voisinage des données synthétiques vise à fournir un repère pour interpréter la valeur obtenue. Cela peut être particulièrement important dans les cas où le générateur G est formé pour produire des images appartenant au 1000 cours sur lequel le réseau Inception a été formé.
En fait, puisque le réseau Inception utilisé pour calculer le score Inception a été formé sur le ImageNet ensemble de données, composé de 1000 cours génériquesil est possible que la répartition des classes apprises par générateur G n’est pas directement représenté dans cet espace sémantique. Cet aspect peut limiter l’interprétabilité du score initial dans le contexte spécifique du problème considéré. En particulier, le réseau Inception pourrait classer à la fois les images de l’ensemble de données d’entraînement et celles générées par le modèle comme appartenant aux mêmes classes ImageNet, produisant des valeurs de non-consistance (mode effondrement)
Dans d’autres scénarios, le score initial peut toujours fournir une indication préliminaire de la qualité des données générées, mais il est toujours nécessaire de combiner le score initial avec d’autres mesures quantitatives afin d’obtenir une évaluation plus complète et plus fiable des performances du modèle génératif.


