
Comment garder les MCP utiles dans les pipelines agentiques
Introduction
les applications alimentées par de grands modèles linguistiques (LLM) nécessitent une intégration avec des services externes, par exemple une intégration avec Google Calendar pour organiser des réunions ou une intégration avec PostgreSQL pour accéder à certaines données.
Appel de fonction
Initialement, ces types d’intégrations étaient implémentés via l’appel de fonction : nous construisions des fonctions spéciales qui peuvent être appelées par un LLM via des jetons spécifiques (LLM générait des jetons spéciaux pour appeler la fonction, en suivant les modèles que nous avions définis), l’analyse et l’exécution. Pour que cela fonctionne, nous implémentions des méthodes d’autorisation et d’appel d’API pour chacun des outils. Surtout, nous avons dû gérer toutes les instructions pour que ces outils soient appelés et construire une logique interne de ces fonctions, y compris des paramètres par défaut ou spécifiques à l’utilisateur. Mais le battage médiatique autour de « l’IA » exigeait des solutions rapides, parfois brutales, pour suivre le rythme, c’est là que les MCP ont été introduits par la société Anthropic.
MCP
MCP signifie Model Context Protocol et c’est aujourd’hui un moyen standard de fournir des outils à la majorité des pipelines agents. Les MCP gèrent essentiellement à la fois les fonctions d’intégration et les instructions LLM pour utiliser les outils. À ce stade, certains pourraient affirmer que les compétences et l’exécution de code qui ont également été introduites récemment par Anthropic ont tué les MCP, mais en fait, ces fonctionnalités ont également tendance à utiliser les MCP pour l’intégration et la gestion des instructions (Exécution de code avec MCP — Anthropic). Les compétences et l’exécution du code sont axées sur le problème de gestion du contexte et d’orchestration des outils, ce qui est un problème différent de ce que sont les MCP. concentré sur.
Les MCP fournissent un moyen standard d’intégrer différents services (outils) avec les LLM et fournissent également des instructions que les LLM utilisent pour appeler les outils. Cependant, voici quelques problèmes :
- Le protocole de contexte de modèle actuel suppose que tous les paramètres d’appel de l’outil soient exposés au LLM, et que toutes leurs valeurs soient supposées être générées par le LLM. Par exemple, cela signifie que le LLM doit générer une valeur d’identifiant utilisateur si l’appel de fonction l’exige. C’est une surcharge car le système, l’application connaît la valeur de l’ID utilisateur sans que LLM ait besoin de la générer. De plus, pour que LLM soit informé de la valeur de l’ID utilisateur, nous devons la mettre à l’invite (il existe une approche de « masquage des arguments » dans FastMCP à partir de gofastmcp qui se concentre spécifiquement sur ce problème, mais je ne l’ai pas vu dans l’implémentation MCP originale d’Anthropic).
- Aucun contrôle immédiat sur les instructions. Les MCP fournissent une description de chaque outil et une description de chaque argument d’un outil, de sorte que ces valeurs sont simplement utilisées aveuglément dans les pipelines agentiques en tant que paramètres d’appel de l’API LLM. Et la description est fournie par chaque développeur de serveur MCP distinct.
Invite système et outils
Lorsque vous appelez des LLM, vous fournissez généralement des outils pour l’appel LLM en tant que paramètre d’appel API. La valeur de ce paramètre est récupérée de la fonction list_tools du MCP qui renvoie le schéma JSON pour les outils dont il dispose.
En même temps, ce paramètre « outils » est utilisé pour ajouter des informations supplémentaires à l’invite système du modèle. Par exemple, le modèle Qwen3-VL a chat_template qui gère l’insertion des outils dans l’invite système de la manière suivante :
“...You are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}...”Ainsi, les descriptions des outils se retrouvent dans l’invite système du LLM que vous appelez.
Le premier problème est en fait partiellement résolu par l’approche mentionnée de « masquage des arguments » de FastMCP, mais j’ai quand même vu des solutions où des valeurs telles que « l’identifiant de l’utilisateur » étaient poussées vers l’invite système du modèle pour l’utiliser dans l’appel de l’outil – c’est juste plus rapide et beaucoup plus simple à mettre en œuvre du point de vue de l’ingénierie (en fait, aucune ingénierie n’est requise pour simplement le mettre à l’invite du système et s’appuyer sur un LLM pour l’utiliser). Je me concentre donc ici sur le deuxième problème.
En même temps, je laisse de côté les problèmes liés aux tonnes de MCP inutiles sur le marché — certains d’entre eux ne fonctionnent pas, certains ont généré une description d’outils qui peut prêter à confusion pour le modèle. Le problème sur lequel je me concentre ici : les outils non standardisés et leurs descriptions de paramètres qui peuvent être la raison pour laquelle les LLM se comportent mal avec certains outils.
Au lieu de la conclusion pour la partie introductive :
Si votre pipeline agent basé sur LLM échoue avec les outils dont vous disposez, vous pouvez :
- Choisissez simplement une API LLM plus puissante, plus moderne et plus coûteuse ;
- Revisitez vos outils et les instructions dans leur ensemble.
Les deux peuvent fonctionner. Prenez votre décision ou demandez à votre assistant IA de prendre une décision à votre place…
Partie formelle du travail — recherche
1. Exemples de différentes descriptions
En recherchant parmi les véritables MCP sur le marché, en vérifiant leurs listes d’outils et leurs descriptions, j’ai pu trouver de nombreux exemples du problème mentionné. Ici, je ne donne qu’un seul exemple de deux MCP différents qui ont également des domaines différents (dans les cas réels, la liste des MCP utilisés par un modèle a tendance à avoir des domaines différents) :
Exemple 1 :
Description de l’outil : « Générer un graphique en aires pour afficher les tendances des données sous des variables indépendantes continues et observer la tendance globale des données, telle que déplacement = vitesse (moyenne ou instantanée) × temps : s = v × t. Si l’axe des x est le temps
Description de la propriété « Données » : « Données pour le graphique en aires, il doit s’agir d’un tableau d’objets, chaque objet contient un champ « temps » et un champ « valeur », tel que : [{ time: ‘2015’, value: 23 }, { time: ‘2016’, value: 32 }]lorsque l’empilement est nécessaire pour une zone, les données doivent contenir un champ « groupe », tel que : [{ time: ‘2015’, value: 23, group: ‘A’ }, { time: ‘2015’, value: 32, group: ‘B’ }].»
Exemple 2 :
Description de l’outil : « Rechercher des annonces Airbnb avec différents filtres et paginations. Fournir des liens directs vers l’utilisateur »,
Description de la propriété « Emplacement » : « Emplacement à rechercher (ville, état, etc.) »
Ici, je ne dis pas qu’aucune de ces descriptions est incorrecte, elles sont simplement très différentes du point de vue du format et des détails.
2. Ensemble de données et référence
Pour prouver que différentes descriptions d’outils peuvent modifier le comportement du modèle, j’ai utilisé celui de NVidia. « Quand2Appel » ensemble de données. À partir de cet ensemble de données, j’ai pris des échantillons de test comportant plusieurs outils parmi lesquels choisir pour le modèle et un outil est le bon choix (il est correct d’appeler un outil spécifique plutôt qu’un autre ou de fournir une réponse textuelle sans aucun appel d’outil, selon l’ensemble de données). L’idée du benchmark est de compter les appels d’outils corrects et incorrects, je compte également les cas « aucun appel d’outil » comme une réponse incorrecte. Pour le LLM, j’ai sélectionné « gpt-5-nano » d’OpenAI.
3. Génération de données
L’ensemble de données d’origine ne fournit qu’une seule description d’outil. Pour créer des descriptions alternatives pour chaque outil et paramètre, j’ai utilisé « gpt-5-mini » pour le générer sur la base de l’actuel avec l’instruction suivante pour le compliquer (après la génération, il y a eu une étape supplémentaire de validation et de régénération si nécessaire) :
« » »Vous recevrez la définition de l’outil au format JSON. Votre tâche est de rendre la description de l’outil plus détaillée, afin qu’elle puisse être utilisée par un modèle faible.
L’une des façons de compliquer est d’insérer une description détaillée de son fonctionnement et des exemples d’utilisation.
Exemple de descriptions détaillées :
Description de l’outil : « Générer un graphique en aires pour afficher les tendances des données sous des variables indépendantes continues et observer la tendance globale des données, telle que déplacement = vitesse (moyenne ou instantanée) × temps : s = v × t. Si l’axe des x est le temps
Description de la propriété : « Données pour le graphique en aires, il doit s’agir d’un tableau d’objets, chaque objet contient un champ « temps » et un champ « valeur », tel que : [{ time: ‘2015’, value: 23 }, { time: ‘2016’, value: 32 }]lorsque l’empilement est nécessaire pour une zone, les données doivent contenir un champ « groupe », tel que : [{ time: ‘2015’, value: 23, group: ‘A’ }, { time: ‘2015’, value: 32, group: ‘B’ }].»
Renvoie la description détaillée mise à jour strictement au format JSON (modifiez simplement les descriptions, ne modifiez pas la structure du JSON saisi). Commencez votre réponse par :
« Nouveau format JSON : … »
« » »
4. Expériences
Pour tester l’hypothèse, j’ai fait quelques tests, à savoir :
- Mesurer la référence de la performance du modèle sur le benchmark sélectionné (Baseline) ;
- Remplacez les descriptions d’outils correctes (y compris à la fois la description de l’outil elle-même et les descriptions des paramètres – les mêmes pour toutes les expériences) par celle générée (outil correct remplacé) ;
- Remplacez les descriptions d’outils incorrectes par celles générées (outil incorrect remplacé) ;
- Remplacez la description de tous les outils par celle générée (Tous les outils remplacés).
Voici un tableau avec les résultats de ces expériences (pour chacune des expériences, 5 évaluations ont été effectuées, donc en plus de l’écart type de précision (std) est fourni) :
| Méthode | Précision moyenne | Norme de précision | Précision maximale sur 5 expériences |
| Référence | 76,5% | 0,03 | 79,0% |
| Outil correct remplacé | 80,5% | 0,03 | 85,2% |
| Outil incorrect remplacé | 75,1% | 0,01 | 76,5% |
| Tous les outils remplacés | 75,3% | 0,04 | 82,7% |
Conclusion
D’après le tableau ci-dessus, il est évident que la complexité des outils introduit un biais dans le modèle ; les LLM sélectionnés ont tendance à choisir l’outil avec une description plus détaillée. Dans le même temps, nous pouvons constater qu’une description étendue peut confondre le modèle (dans le cas de tous les outils remplacés).
Le tableau montre que la description des outils fournit des mécanismes pour manipuler et ajuster de manière significative le comportement/la précision du modèle, en particulier en tenant compte du fait que le benchmark sélectionné fonctionne avec un petit nombre d’outils à chaque appel de modèle, le nombre moyen d’outils utilisés pour chaque échantillon est de 4,35.
Dans le même temps, cela indique clairement que les LLM peuvent avoir des biais en matière d’outils qui peuvent potentiellement être mal utilisés par les fournisseurs de MCP, qui peuvent être des biais similaires à ceux que j’ai signalés auparavant — biais de style. La recherche des biais et de leur utilisation abusive peut être importante pour des études ultérieures.
Ingénierie d’une solution
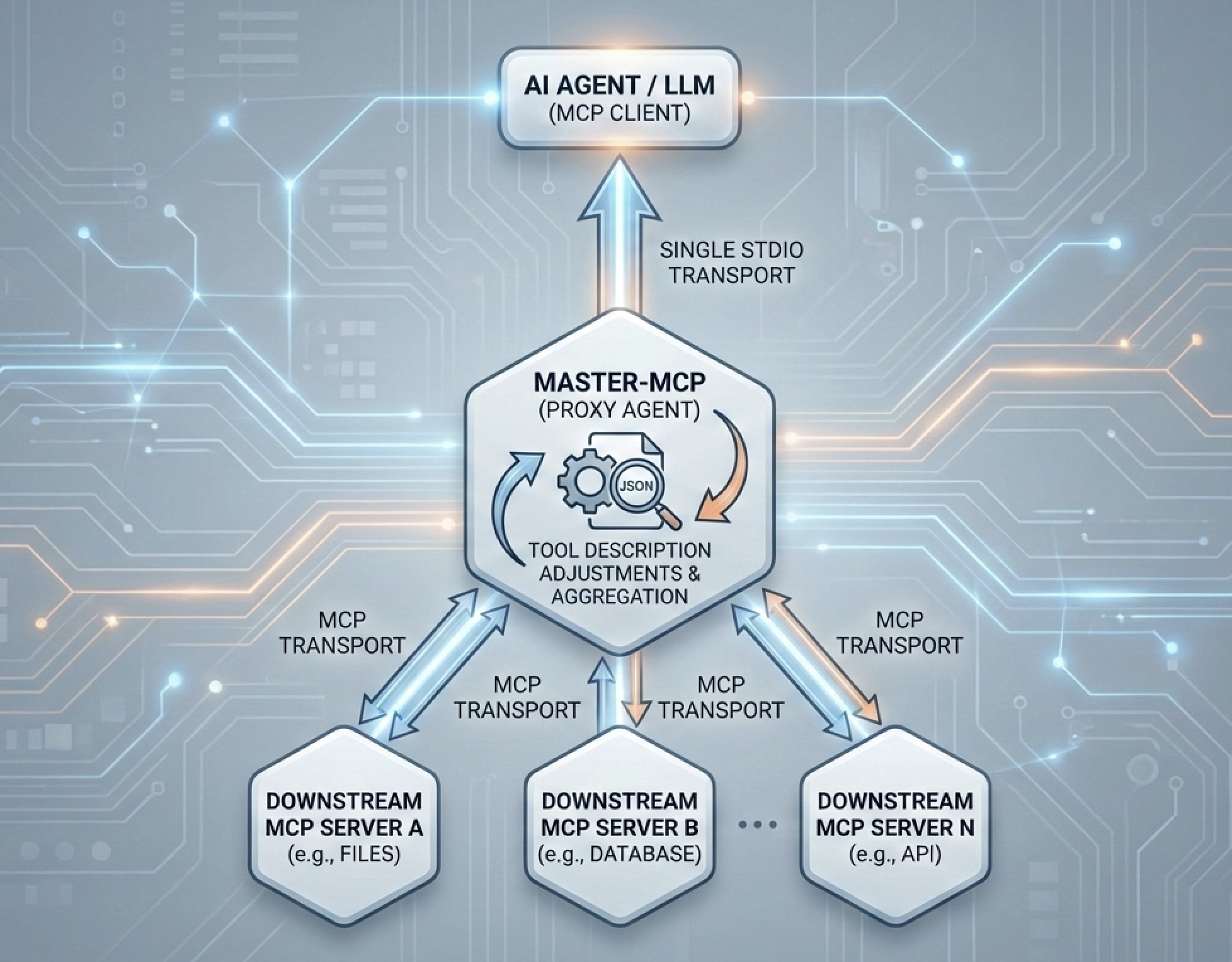
J’ai préparé un PoC d’outils pour résoudre le problème mentionné dans la pratique – Master-MCP. Master-MCP est un serveur proxy MCP qui peut être connecté à n’importe quel nombre de MCP et peut également être connecté à un agent/LLM en tant que serveur MCP unique lui-même (actuellement serveur MCP stdio-transport). Fonctionnalités par défaut du Master-MCP que j’ai implémenté :
- Ignorez certains paramètres. La mécanique implémentée exclut tous les paramètres commençant par le symbole « _ » du schéma des paramètres de l’outil. Plus tard, ce paramètre peut être inséré par programme ou utiliser la valeur par défaut (si fournie).
- Ajustements de la description de l’outil. Master-MCP collecte tous les outils et leurs descriptions à partir des serveurs MCP connectés et fournit à l’utilisateur un moyen de l’ajuster. Il expose une méthode avec une interface utilisateur simple pour modifier cette liste (schéma JSON), afin que l’utilisateur puisse expérimenter les descriptions de différents outils.
J’invite toutes les personnes intéressées à rejoindre le projet. Avec le soutien de la communauté, les plans peuvent inclure l’extension des fonctionnalités de Master-MCP, par exemple :
- Journalisation et surveillance suivies d’analyses avancées ;
- Hiérarchie et orchestration des outils (y compris basés sur le ML) pour combiner à la fois des techniques modernes de gestion de contexte et des algorithmes intelligents.
Page github actuelle du projet : lien


