
Implémentation du Vibe Proving avec l’apprentissage par renforcement
« Le développement des mathématiques vers une plus grande précision a conduit, comme on le sait, à la formalisation de grandes parties de celles-ci, de sorte que l’on peut prouver n’importe quel théorème en utilisant uniquement quelques règles mécaniques. »
— K. Gödel
Dans la première partie, nous avons construit un vérificateur de preuves et développé un modèle mental expliquant pourquoi nous devrions faire confiance aux preuves issues d’un LLM : tant que nous avons un raisonnement formalisé et un vérificateur solide, « quelques règles mécaniques » suffisent. Alors comment pouvons-nous former un LLM pour générer des preuves valides ?
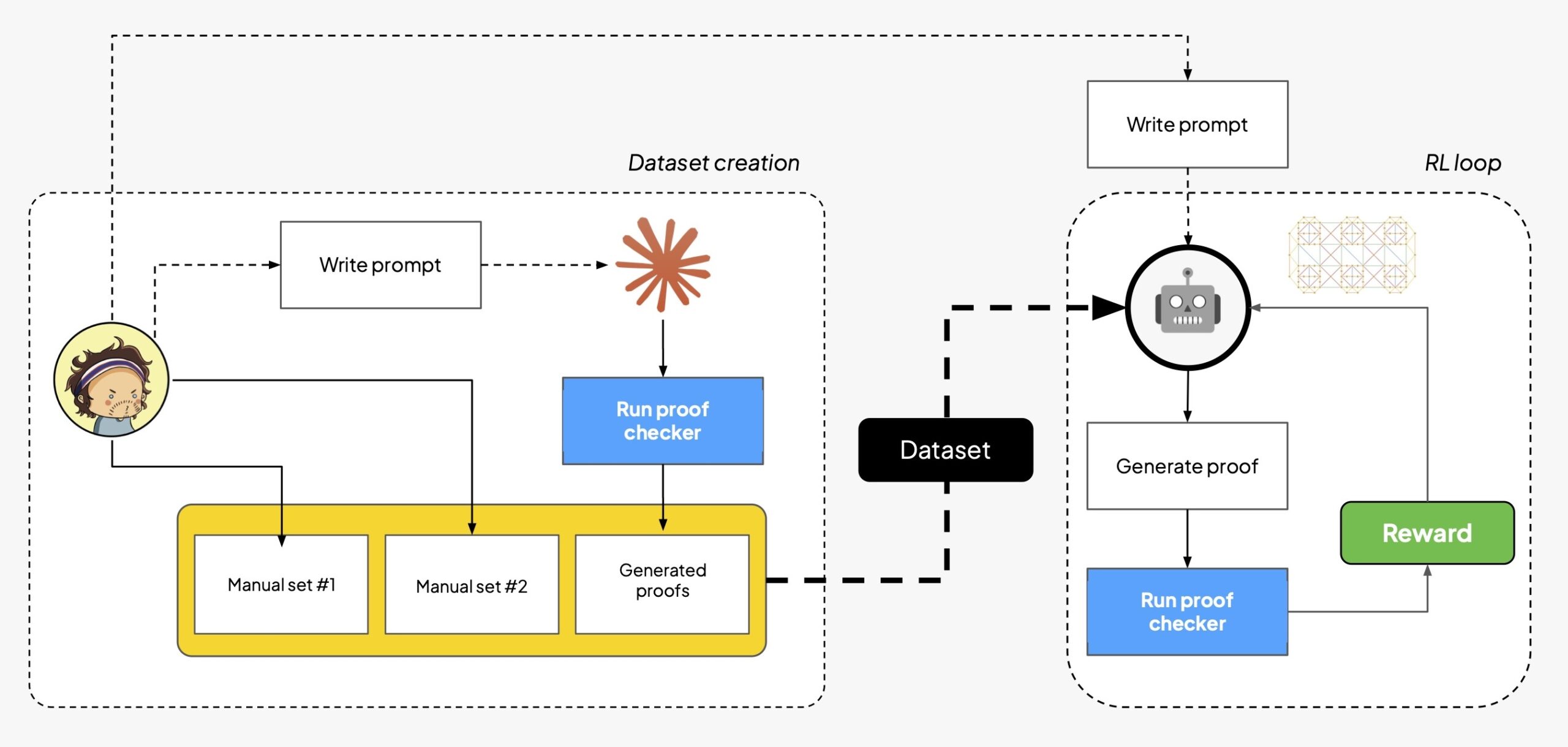
Comme DeepSeek magnifiquement montréla même intuition derrière l’IA apprendre le jeu de Go fonctionne pour l’IA qui apprend à raisonner, à condition que le raisonnement puisse être vérifié (et nous savons maintenant que c’est possible). Dans cette deuxième partie, nous utilisons à bon escient notre vérificateur et construisons une boucle de formation RL de bout en bout pour affiner un modèle open source afin de produire des preuves dans le langage que nous avons introduit dans la partie 1 : en un coup d’œil, la figure suivante montre les ingrédients de base du flux.

TL;DR : après une collaboration machine-humaine pour générer un ensemble de données (en utilisant notre vérificateur comme contrôle d’intégrité sur les exemples générés par LLM), nous courons sur Bricoler une boucle RL à faire LoRA-ajustement fin du style des modèles open source. Nous indiquons au modèle (1) comment fonctionne notre langage, (2) comment appliquer des règles pour construire des preuves et (3) comment formater les réponses afin qu’elles soient faciles à analyser. Chaque preuve est ensuite passée par le vérificateur de preuves, et la récompense est propagée pour améliorer les capacités du modèle : idéalement, le modèle commencera avec des tentatives de preuve pour la plupart infructueuses, puis s’améliorera progressivement au fur et à mesure de la progression de la formation.
Notez que même si la série cible spécifiquement le raisonnement mathématique, les preuves vérifiables sont fondamentales pour renforcer la confiance dans les systèmes logiciels distribués. Comme certains experts argumentél’IA pourrait bien être l’ingrédient manquant pour prouver l’exactitude du logiciel à grande échelle !
Attachez votre ceinture, clonez le dépôt, et codez le long. Si vous avez sauté la première partie, vous pouvez la lire ici !
Génération d’ensembles de données
« Les gens pensent que les mathématiques sont compliquées. Les mathématiques, c’est la partie la plus simple. Ce sont les choses que nous pouvons comprendre. Ce sont les chats qui sont compliqués. » — J.Conway
Pour obtenir une récompense pour améliorer notre modèle, nous avons d’abord besoin d’exemples de preuves : idéalement, nous aimerions un mélange de preuves faciles et concrètes, écrites dans notre propre langage de raisonnement. Nous ne pouvons pas simplement générer des chaînes aléatoires dans notre alphabet parce que nous aimerions que le modèle essaie de prouver des choses dont nous savons qu’elles sont prouvables en premier lieu ! Comment amorcer le processus ?
Notre mélange de formation est une combinaison de trois sources :
- Une traduction manuelle des exercices (prémisses->conclusion) tirés de pour tousque nous supposons être des preuves résolubles ;
- Une traduction manuelle des exercices (prémisses->conclusion) tirés de Langage, preuve et logiqueque nous supposons être des preuves résolubles ;
- Un corpus de preuves généré par un puissant LLM (Sonnet by Anthropic). Puisque nous ne pouvons pas supposer que les tuples locaux->conclusion générés par LLM sont corrects, nous invitons le LLM à générer un preuve complètequi (vous l’aurez deviné !) est vérifié par notre vérificateur d’épreuves avant d’être ajouté à l’ensemble de formation.
Une seule observation dans l’ensemble de données ressemble à l’objet suivant :
{"premises": ["P", "Q"], "conclusion": "P and Q", "num_steps": 1}
c’est-à-dire un ensemble de prémisses, une conclusion et le nombre d’étapes prises par Sonnet pour générer une preuve valide : les prémisses et la conclusion se retrouveront dans l’invite pendant RL (car nous demanderons au modèle de trouver une preuve de la conclusion à partir des prémisses), et num_steps est une valeur pratique pour imprimer des statistiques sur la difficulté perçue de l’ensemble de formation (en supposant pour simplifier que la longueur d’une preuve est vaguement corrélée à sa difficulté).
Apprentissage par renforcement sur Tinker
« La meilleure façon d’avoir une bonne idée est d’avoir beaucoup d’idées. »
— attribué à L. «
Nous sommes maintenant prêts à obtenir notre propre LLM open source, plus petit, pour Vibe Proving. Il existe de nombreuses recettes et services en ligne pour effectuer du RL sur des modèles open source, mais nous avons choisi Tinker car il promet de supprimer l’infrastructure et la plupart des passe-partout requis (c’est aussi le petit nouveau du quartier, c’est donc une chance de le tester !).
La boucle de formation en elle-même ne réserve pas beaucoup de surprises :
- Échantillon: étant donné l’invite et un tuple (prémisses->conclusion), nous demandons au modèle de générer plusieurs tentatives de preuve.
- Vérifier: nous exécutons chaque tentative via le vérificateur de preuves.
- Récompense: preuves valides (c’est-à-dire des preuves entièrement analysables et logiquement correctes) obtenez la récompense 1, tous les autres résultats obtiennent 0 (‘Faire ou ne pas faire‘, en effet). Notez que nous vérifions également que la preuve générée a les mêmes (prémisses->conclusion) que notre demande, pour éviter que le LLM ne joue facilement avec le système en produisant toujours une preuve trivialement correcte.
- Mise à jour: nous ajustons les poids du modèle pour rendre les preuves réussies plus probables.
Suivant Les propres directives de Tinkernous choisissons d’expérimenter des modèles de raisonnement du MoE dans quelques tailles : gpt-oss-20b, gpt-oss-120b et Qwen3-30B-A3B-Instruct-2507. Pendant la formation, les journaux et les preuves sont stockés dans le training_logs dossier : à la fin, notre application (codée en ambiance !) peut être utilisée pour visualiser les tendances métriques et inspecter les preuves générées.

Si vous utilisez un assistant IA pour surveiller la formation (que j’ai expérimenté pour la première fois avec ce projet), une tranche de données intéressante à suivre est celle des preuves des manuels, car elles sont conçu être délicat. À titre d’exemple, voici une mise à jour de statut de Claude Code :

Dans quelle mesure notre ambiance est-elle bonne ?
Après quelques exécutions et un peu de bricolage avec les paramètres, nous nous retrouvons toujours avec des modèles qui peuvent prouver la majorité des exemples générés, mais qui ont du mal avec certaines preuves de manuels. Il est instructif et légèrement amusant d’inspecter les épreuves générées.
Du côté du succès, il s’agit d’une tentative de prouver La loi de DeMorganc’est-à-dire montrant comment passer de ['not A or not B'] à not (A and B)en supposant d’abord A and B et prouvant une contradiction :
- pas A ou pas B (prémisse)
- | A et B (sous-preuve)
- | Un (2)
- | B (2)
- || pas A (sous-preuve imbriquée, à partir de 1)
- || ~ (3,5)
- || pas B (sous-preuve imbriquée)
- || ~ (4,7)
- | (1, 5-6, 7-8)
- CQD
Du côté des échecs, aucun modèle n’a fait ses preuves 'A or B', 'not A or C', 'not B or D' que C or D peinant à gérer correctement les sous-preuves imbriquées et à appliquer la règle de l’explosion, comme le montre cette trace :
- A ou B (local)
- pas A ou C (prémisse)
- pas B ou D (prémisse)
- | A (sous-preuve)
- || pas A (sous-preuve imbriquée)
- || ~ (4,5)
- | C (5-6) ← ERREUR
- ….
À quel point Tinker était-il facile ?
Notre petite preuve de concept n’est pas vraiment un test de résistance pour un service de formation à grande échelle, mais elle a suffi pour avoir quelques impressions concrètes du système.
La combinaison de bons exemples publics, d’une documentation conviviale pour Claude et d’une abstraction matérielle a permis une introduction agréable et douce à RL, à un coût raisonnable (toutes les expériences pour le billet de blog coûtent environ 60 $, y compris les exécutions initiales qui – avec le recul ! – étaient évidemment une perte de temps et d’argent !).
Lorsque vous comprenez et commencez à exécuter quelques tâches en parallèle, le manque de surveillance et d’observabilité devient un problème : parfois mes exécutions ralentissent considérablement (obtenant try_again réponses pendant une longue période, comme si le système était surchargé), et certaines tâches ont échoué à un moment donné pour des raisons peu claires (mais, bien sûr, vous pouvez redémarrer à partir d’un point de contrôle précédent). Compte tenu du prix raisonnable et de la nature prototype de mes charges de travail, aucun de ces problèmes ne l’emportait sur les avantages, et je suis reparti avec une expérience Tinker suffisamment positive pour que je l’utiliserais certainement à nouveau pour un futur projet.
À bientôt, cowboys de RL !
« Nous faisons ces choses non pas parce qu’elles sont faciles, mais parce que nous pensions qu’elles allaient être faciles. » – Anonyme
Bien que Tinker rend effectivement le processus de formation (essentiellement) transparent, le diable est toujours dans les détails (RL) : nous avons à peine effleuré la surface jusqu’à présent, car notre objectif était de passer de zéro à une pile Vibe Proving, sans optimiser RL. en soi.
La bonne nouvelle est que le flux est assez modulaire, de sorte que tous les composants peuvent être améliorés et bricolés (en quelque sorte) indépendamment :
- choix du modèle : type de modèle, taille du modèle, fournisseur…
- paramètres d’entraînement : taux d’apprentissage du choix, taille du lot, classement LoRA…
- abstractions de code : réécrivez le code avec Env. RL …
- optimisation rapide : meilleures instructions, formatage plus facile, exemples utiles en contexte, …
- optimisation des jeux de données : exemples plus diversifiés, apprentissage du programme (pas seulement varier la difficulté de la preuve, mais par exemple commencer par des preuves qui sont faites à l’exception d’une étape manquante, puis des preuves avec deux étapes manquantes, etc. jusqu’à ce que le modèle doive remplir toute la preuve)…
Dans le même ordre d’idées, notre propre langage de preuve personnalisé n’est certainement pas suffisant pour obtenir des résultats intéressants : nous pourrait l’améliorer, mais parvenir à quelque chose d’utilisable nécessiterait en réalité une quantité de travail incroyable. Pour ces raisons, il est préférable de migrer vers un langage spécialement conçu, tel que Maigre: plus important encore, maintenant que vous connaissez les preuves en tant que raisonnement formalisé, le même modèle mental se transpose dans un langage (beaucoup) plus expressif. De plus, le Lean possède à peu près les même style pour écrire des preuvesc’est-à-dire les règles d’introduction et d’élimination des opérateurs logiques.
En d’autres termes, une fois que nous avons maîtrisé les calculs derrière Vibe Proving et construit un harnais RL initial, ce qui reste est une bonne vieille ingénierie.
Remerciements
Merci à Patrick John Chia, Federico Bianchi, Ethan Rosenthal, Ryan Vilim, Davis Treybig pour leurs précieux commentaires sur les versions précédentes de cette version.
Si vous aimez l’intersection de genAI, du raisonnement sur les systèmes distribués et de la vérification, vous pouvez également consulter notre recherche à Bauplan.
Des assistants de codage IA ont été utilisés pour écrire le référentiel compagnon, mais aucun assistant n’a été utilisé pour écrire le texte (si ce n’est pour la relecture et la correction des fautes de frappe).


