
Le « Calendrier de l’Avent » du Machine Learning Jour 22 : Intégrations dans Excel
de cette série, nous parlerons de apprentissage profond.
Et lorsque les gens parlent d’apprentissage profond, nous pensons immédiatement à ces images d’architectures de réseaux neuronaux profonds, avec de nombreuses couches, neurones et paramètres.
En pratique, le véritable changement introduit par le deep learning est ailleurs.
Il s’agit de apprentissage des représentations de données.
Dans cet article, nous nous concentrons sur intégrations de texteexpliquez leur rôle dans le paysage de l’apprentissage automatique et montrez comment ils peuvent être compris et exploré dans Excel.
1. Gains automatiques classiques vs apprentissage profond
Nous discuterons, dans cette partie, de la raison pour laquelle l’intégration est introduite.
1.1 Quelle est la place de l’apprentissage profond ?
Pour comprendre les intégrations, il faut d’abord clarifier la place du deep learning.
Nous utiliserons le terme apprentissage automatique classique pour décrire des méthodes qui ne s’appuient pas sur des architectures profondes.
Tous les articles précédents traitent du machine learning classique, qui peut être décrit de deux manières complémentaires.
Paradigmes d’apprentissage
- Apprentissage supervisé
- Apprentissage non supervisé
Familles modèles
- Modèles basés sur la distance
- Modèles basés sur des arbres
- Modèles basés sur le poids
Dans cette série, nous avons déjà étudié les algorithmes d’apprentissage derrière ces modèles. Nous avons notamment vu que descente de pente s’applique à tous les modèles basés sur le poids, de la régression linéaire aux réseaux de neurones.
L’apprentissage profond est souvent réduit à des réseaux de neurones comportant de nombreuses couches.
Mais cette explication est incomplète.
D’un point de vue optimisation, le deep learning n’introduit pas de nouvelle règle d’apprentissage.
Alors qu’est-ce que cela introduit ?
1.2 L’apprentissage profond comme apprentissage de la représentation des données
L’apprentissage profond concerne comment les fonctionnalités sont créées.
Au lieu de concevoir manuellement des fonctionnalités, le deep learning apprend automatiquement les représentationssouvent à travers de multiples transformations successives.
Cela soulève également une question conceptuelle importante :
Quelle est la frontière entre l’ingénierie des fonctionnalités et l’apprentissage des modèles ?
Quelques exemples montrent cela plus clairement :
- La régression polynomiale est toujours un modèle linéaire, mais les caractéristiques sont polynomiales
- Les méthodes du noyau projettent les données dans un espace de fonctionnalités de grande dimension
- Les méthodes basées sur la densité transforment implicitement les données avant l’apprentissage
L’apprentissage profond poursuit cette idée, mais à grande échelle.
De ce point de vue, le deep learning appartient à :
- le philosophie d’ingénierie des fonctionnalitéspour la représentation
- le famille de modèles basée sur le poidspour apprendre
1.3 Images et réseaux de neurones convolutifs
Les images sont représentées comme pixels.
D’un point de vue technique, les données images sont déjà numériques et structurées : une grille de nombres. Cependant, le information contenu dans ces pixels n’est pas structuré d’une manière que les modèles classiques peuvent facilement exploiter.
Les pixels n’encodent pas explicitement : les bords, les formes, les textures ou les objets.
Les réseaux de neurones convolutifs (CNN) sont conçus pour créer des informations à partir de pixels. Ils appliquent des filtres pour détecter des modèles locaux, puis les combinent progressivement en représentations de niveau supérieur.
J’ai publié cet article montrant comment les CNN peuvent être implémentés dans Excel pour rendre ce processus explicite.

Pour les images, le défi est pas rendre les données numériques, mais extraire des représentations significatives à partir de données déjà numériques.
1.4 Données texte : un problème différent
Le texte présente un défi fondamentalement différent.
Contrairement aux images, le texte est non numérique par nature.
Avant de modéliser le contexte ou l’ordre, le premier problème est plus fondamental :
Comment représenter numériquement les mots ?
Créer une représentation numérique pour le texte est la première étape.
Dans le deep learning pour le texte, cette étape est gérée par intégrations.
Les intégrations transforment les symboles discrets (mots) en vecteurs avec lesquels les modèles peuvent fonctionner. Une fois les plongements existants, nous pouvons alors modéliser : le contexte, l’ordre et les relations entre les mots.
Dans cet article, nous nous concentrons sur cette première et essentielle étape :
comment les intégrations créent des représentations numériques pour le texteet comment ce processus peut être exploré dans Excel.
2. Deux façons d’apprendre les intégrations de texte
Dans cet article, nous utiliserons le Ensemble de données de critiques de films IMDB pour illustrer les deux approches. L’ensemble de données est distribué sous la licence Apache 2.0.
Il existe deux manières principales d’apprendre les intégrations de texte, et nous ferons les deux avec cet ensemble de données :
- supervisé : nous créerons des intégrations pour prédire le sentiment
- non supervisé ou auto-supervisé : nous utiliserons l’algorithme word2vec
Dans les deux cas, le but est le même :
pour transformer les mots en vecteurs numériques pouvant être utilisés par des modèles d’apprentissage automatique.
Avant de comparer ces deux approches, nous devons d’abord clarifier ce que sont les intégrations et comment elles se rapportent à l’apprentissage automatique classique.

2.1 Embeddings et apprentissage automatique classique
Dans le machine learning classique, les données catégorielles sont généralement traitées avec :
- encodage des étiquettesqui attribue des entiers fixes mais introduit un ordre artificiel
- encodage à chaudqui supprime l’ordre mais produit des vecteurs clairsemés de grande dimension
La manière dont ils peuvent être utilisés dépend de la nature des modèles.
Modèles basés sur la distance ne peut pas utiliser efficacement l’encodage one-hot, car toutes les catégories finissent par être à égale distance les unes des autres. L’encodage des étiquettes ne pourrait fonctionner que si l’on pouvait attribuer des valeurs numériques significatives aux catégories, ce qui n’est généralement pas le cas dans les modèles classiques.
Modèles basés sur le poids peut utiliser un codage à chaud, car le modèle apprend un poids pour chaque catégorie. En revanche, avec le codage d’étiquettes, les valeurs numériques sont fixes et ne peuvent pas être ajustées pour représenter des relations significatives.
Modèles basés sur des arbres traiter toutes les variables comme des divisions catégorielles plutôt que comme des grandeurs numériques, ce qui rend le codage des étiquettes acceptable dans la pratique. Cependant, la plupart des implémentations, y compris scikit-learn, nécessitent toujours des entrées numériques. En conséquence, les catégories doivent être converties en nombres, soit via un codage d’étiquette, soit par un codage à chaud. Si les valeurs numériques avaient une signification sémantique, cela serait encore une fois bénéfique.
Globalement, cela met en évidence une limite des approches classiques :
les valeurs des catégories sont fixes et non apprises.
Les intégrations étendent cette idée en apprendre la représentation elle-même.
Chaque mot est associé à un vecteur entraînable, transformant la représentation des catégories en un problème d’apprentissage plutôt qu’en une étape de prétraitement.
2.2 Intégrations supervisées
Dans l’apprentissage supervisé, les plongements sont appris dans le cadre d’une tâche de prédiction.
Par exemple, l’ensemble de données IMDB contient des étiquettes sur l’analyse des sentiments. On peut donc créer une architecture très simple :
Dans notre cas, nous pouvons utiliser une architecture très simple : chaque mot est mappé à un intégration unidimensionnelle
Ceci est possible car l’objectif est une classification binaire des sentiments.

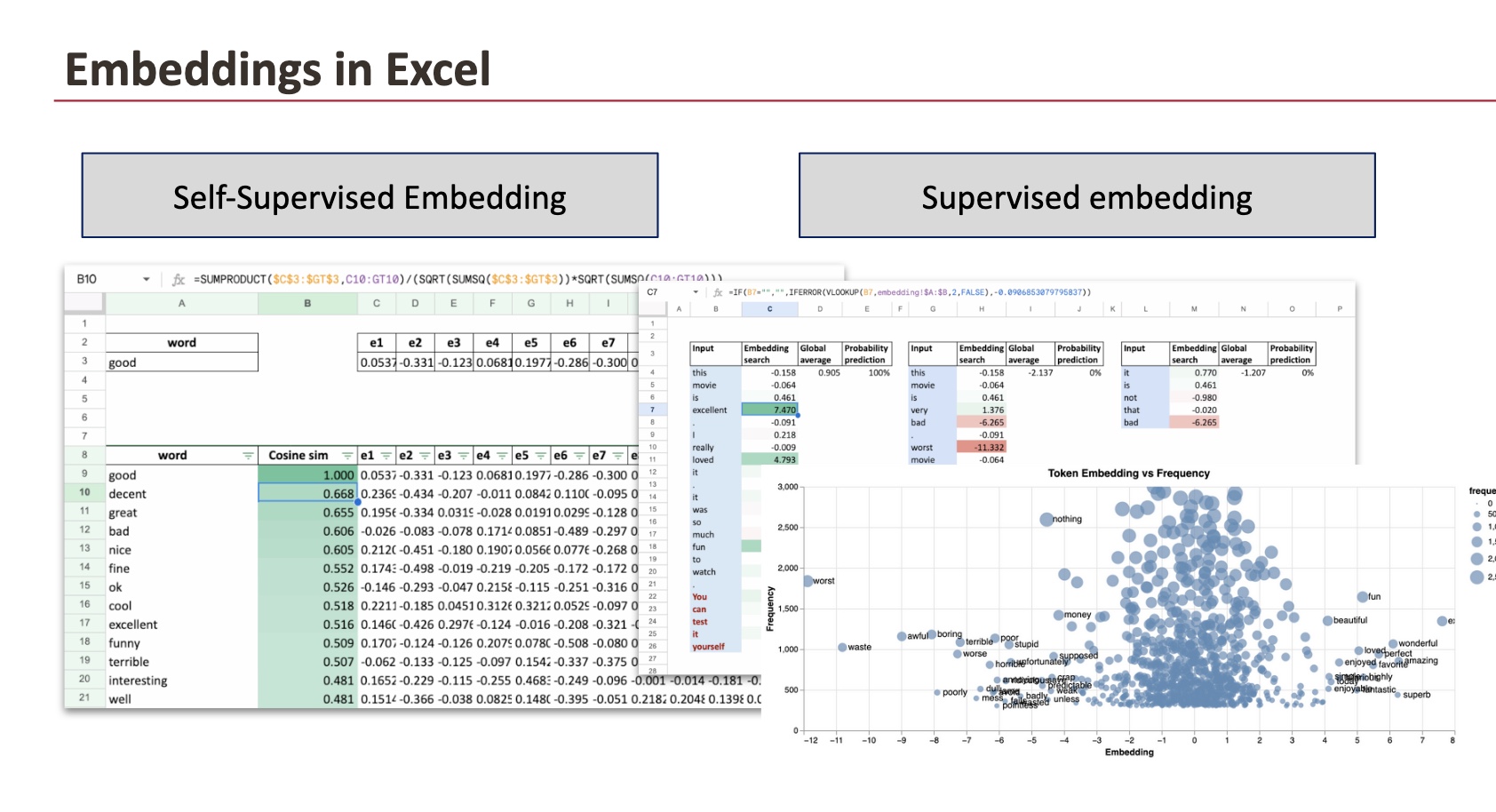
Une fois la formation terminée, nous pouvons exporter les intégrations et explorez-les dans Excel.
Lors du traçage des intégrations sur l’axe des x et de la fréquence des mots sur l’axe des y, un modèle clair apparaît :
- les valeurs positives sont associées à des mots tels que excellent ou merveilleux,
- les valeurs négatives sont associées à des mots tels que pire ou déchets
En fonction de l’initialisation, le signe peut être inversé, puisque la couche de régression logistique possède également des paramètres qui influencent la prédiction finale.

Enfin, dans Excel, nous reconstruisons le pipeline complet qui correspond à l’architecture que nous avons définie au début.
Colonne d’entrée
Le texte saisi (une critique) est découpé en mots et chaque ligne correspond à un mot.
Recherche intégrée
À l’aide d’une fonction de recherche, la valeur d’intégration associée à chaque mot est récupérée à partir de la table d’intégration apprise lors de la formation.
Moyenne mondiale
L’intégration moyenne globale est calculée en faisant la moyenne des intégrations de tous les mots vus jusqu’à présent. Cela correspond à une représentation de phrase très simple : la moyenne des vecteurs de mots.
Prédiction de probabilité
L’intégration moyenne est ensuite transmise à une fonction logistique pour produire une probabilité de sentiment.

Ce que nous observons
- Mots avec fortement intégrations positives (Par exemple excellent, amour, amusant) poussent la moyenne vers le haut.
- Mots avec fortement intégrations négatives (Par exemple pire, horrible, déchets) tire la moyenne vers le bas.
- Les mots neutres ou faiblement pondérés ont peu d’influence.
À mesure que d’autres mots sont ajoutés, l’intégration moyenne mondiale se stabilise et la prédiction du sentiment devient plus confiante.
2.3 Word2Vec : intégrations de cooccurrence
Dans Word2Vec, la similitude ne veut pas dire que deux mots ont le même sens.
Cela veut dire qu’ils apparaître dans des contextes similaires.
Word2Vec apprend les incorporations de mots en regardant quels mots ont tendance à coexister dans une fenêtre fixe dans le texte. Deux mots sont considérés comme similaires s’ils apparaissent souvent autour des mêmes mots voisinsmême si leurs significations sont opposées.
Comme le montre la feuille Excel ci-dessous, nous calculons la similarité cosinus pour le mot bien et récupérez les mots les plus similaires.

Du point de vue du modèle, les mots environnants sont presque identiques. La seule chose qui change, c’est l’adjectif lui-même.
En conséquence, Word2Vec apprend que « bon » et « mauvais » jouent un rôle similaire dans le langagemême si leurs significations sont opposées.
Ainsi, Word2Vec capture similarité de distributionpas de polarité sémantique.
Une façon utile d’y réfléchir est la suivante :
Les mots sont proches s’ils sont utilisés aux mêmes endroits.
2.4 Comment les intégrations sont utilisées
Dans les systèmes modernes tels que RAG (génération augmentée par récupération)les intégrations sont souvent utilisées pour récupérer des documents ou des passages pour répondre à des questions.
Cependant, cette approche présente des limites.
Les intégrations les plus couramment utilisées sont formées dans un auto-supervisé manière, sur la base d’objectifs de cooccurrence ou de prédiction contextuelle. En conséquence, ils capturent la similitude générale du langage, et non la signification spécifique à une tâche.
Cela signifie que :
- les intégrations peuvent récupérer un texte linguistiquement similaire mais pas pertinent
- la proximité sémantique ne garantit pas exactitude de la réponse
D’autres stratégies d’intégration peuvent être utilisées, notamment les intégrations adaptées aux tâches ou supervisées, mais elles restent souvent auto-supervisées à la base.
Comprendre comment les intégrations sont créées, ce qu’elles codent et ce qu’elles ne codent pas est donc essentielle avant de les utiliser dans des systèmes en aval tels que RAG.
Conclusion
Les incorporations sont des représentations numériques apprises de mots qui rendent la similarité mesurable.
Qu’elles soient apprises par supervision ou par cooccurrence, les intégrations mappent les mots à des vecteurs en fonction de la manière dont ils sont utilisés dans les données. En les exportant vers Excel, nous pouvons inspecter ces représentations directement, calculer les similitudes et comprendre ce qu’elles capturent et ce qu’elles ne capturent pas.
Cela rend les intégrations moins mystérieuses et clarifie leur rôle de base pour des systèmes plus complexes tels que la récupération ou le RAG.


