
Le « Calendrier de l’Avent » de Machine Learning Jour 4 : k-Means dans Excel
4 du calendrier de l’Avent Machine Learning.
Durant les trois premiers jours, nous avons exploré modèles basés sur la distance pour l’apprentissage supervisé :
Dans tous ces modèles, l’idée était la même : nous mesurons les distances et nous décidons du résultat en fonction des points les plus proches ou des centres les plus proches.
Aujourd’hui, on reste dans cette même famille d’idées. Mais nous utilisons les distances de manière non encadrée : k-signifie.
Maintenant, une question pour ceux qui connaissent déjà cet algorithme : k-means ressemble plus à quel modèle, au classificateur k-NN ou au classificateur centroïde le plus proche ?
Et si vous vous en souvenez, pour tous les modèles que nous avons vus jusqu’à présent, il n’y avait pas vraiment de phase « d’entraînement » ni de réglage des hyperparamètres.
- Pour k-NN, il n’y a aucune formation du tout.
- Pour LDA, QDA ou GNB, la formation consiste simplement à calculer des moyennes et des écarts. Et il n’y a pas non plus de véritables hyperparamètres.
Maintenant, avec k-means, nous allons implémenter un algorithme de formation qui ressemble enfin à du « vrai » apprentissage automatique.
Nous commençons par un petit exemple 1D. Ensuite on passe à la 2D.
Objectif des k-moyennes
Dans l’ensemble de données de formation, il y a pas d’étiquettes initiales.
Le but de k-means est de créer des étiquettes significatives en regroupant les points proches les uns des autres.
Regardons l’illustration ci-dessous. Vous pouvez clairement voir deux groupes de points. Chaque centroïde (le carré rouge et le carré vert) se trouve au milieu de son cluster et chaque point est attribué au plus proche.
Cela donne une image très intuitive de la façon dont k-means découvre la structure en utilisant uniquement les distances.
Et ici, k signifie le nombre de centres que nous essayons de trouver.

Maintenant, répondons à la question : De quel algorithme k-means est-il le plus proche, du classificateur k-NN ou du classificateur centroïde le plus proche ?
Ne vous laissez pas berner par le k en k-NN et k-moyennes.
Ils ne veulent pas dire la même chose :
- dans k-NN, k est le nombre de voisins, pas le nombre de classes ;
- dans k-signifie, k est le nombre de centroïdes.
K-means est beaucoup plus proche du Classificateur centroïde le plus proche.
Les deux modèles sont représentés par centroïdeset pour une nouvelle observation, nous calculons simplement la distance à chaque centroïde pour décider à lequel il appartient.
La différence, bien sûr, c’est que dans le Classificateur centroïde le plus prochenous avons déjà savoir les centroïdes car ils proviennent de classes étiquetées.
Dans k-signifienous ne connaissons pas les centroïdes. Le but de l’algorithme est de découvrir ceux qui conviennent directement à partir des données.
Le problème business est complètement différent : au lieu de prédire les étiquettes, on essaie de créer eux.
Et en k-moyennes, la valeur de k (le nombre de centroïdes) est inconnu. Cela devient donc un hyperparamètre que nous pouvons régler.
k-means avec une seule fonctionnalité
Nous commençons par un petit exemple 1D pour que tout soit visible sur un seul axe. Et nous choisirons les valeurs de manière si triviale que nous pourrons voir instantanément les deux centroïdes.
1, 2, 3, 11, 12, 13
Oui, 2 et 12.
Mais comment l’ordinateur le saurait-il ? La machine « apprendra » en devinant étape par étape.
Voici l’algorithme appelé L’algorithme de Lloyd.
Nous allons l’implémenter dans Excel avec la boucle suivante :
- choisir les centroïdes initiaux
- calculer la distance de chaque point à chaque centre de gravité
- attribuer chaque point au centre de gravité le plus proche
- recalculer les centroïdes comme la moyenne des points de chaque cluster
- répétez les étapes 2 à 4 jusqu’à ce que les centroïdes ne bougent plus
1. Choisissez les centroïdes initiaux
Choisissez deux centres initiaux, par exemple :
Ils doivent se situer dans la plage de données (entre 1 et 13).

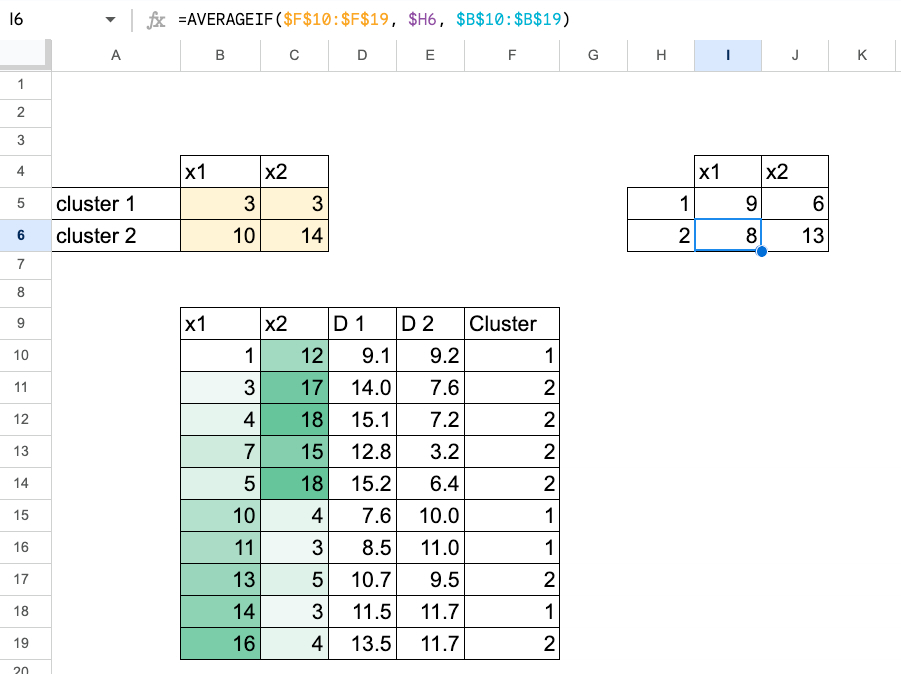
2. Calculer les distances
Pour chaque point de données x :
- calculer la distance à c_1,
- calculez la distance à c_2.
Généralement, nous utilisons la distance absolue en 1D.
Nous avons maintenant deux valeurs de distance pour chaque point.

3. Attribuer des clusters
Pour chaque point :
- comparer les deux distances,
- attribuez le cluster du plus petit (1 ou 2).
Dans Excel, c’est simple IF ou MIN logique basée.

4. Calculez les nouveaux centroïdes
Pour chaque cluster :
- prendre les points attribués à ce cluster,
- calculer leur moyenne,
- cette moyenne devient le nouveau centre de gravité.

5. Itérer jusqu’à atteindre la convergence
Désormais dans Excel, grâce aux formules, on peut simplement collez les nouvelles valeurs du centroïde dans les cellules des centroïdes initiaux.
La mise à jour est immédiate et après avoir effectué cette opération plusieurs fois, vous verrez que les valeurs cessent de changer. C’est alors que l’algorithme a convergé.

Nous pouvons également enregistrer chaque étape dans Excel afin de voir comment les centroïdes et les clusters évoluent au fil du temps.

k-means avec deux fonctionnalités
Utilisons maintenant deux fonctionnalités. Le processus est exactement le même, on utilise simplement la distance euclidienne en 2D.
Vous pouvez soit faire le copier-coller les nouveaux centroïdes comme valeurs (avec juste quelques cellules à mettre à jour),

ou vous pouvez afficher toutes les étapes intermédiaires pour voir l’évolution complète de l’algorithme.

Visualisation des centroïdes mobiles dans Excel
Pour rendre le processus plus intuitif, il est utile de créer des tracés montrant comment les centroïdes se déplacent.
Malheureusement, Excel ou Google Sheets ne sont pas idéaux pour ce genre de visualisation, et les tableaux de données deviennent vite un peu complexes à organiser.
Si vous souhaitez voir un exemple complet avec des tracés détaillés, vous pouvez lire cet article J’ai écrit il y a presque trois ans, où chaque étape du mouvement du centroïde est clairement montrée.

Comme vous pouvez le voir sur cette image, la feuille de travail est devenue assez désorganisée, surtout par rapport au tableau précédent, qui était très simple.

Choisir le k optimal : la méthode du coude
Alors maintenant, il est possible d’essayer k = 2 et k = 3 dans notre cas, et calculons l’inertie pour chacun. Ensuite, nous comparons simplement les valeurs.
On peut même commencer avec k=1.
Pour chaque valeur de k :
- nous exécutons k-Means jusqu’à convergence,
- calculer le inertiequi est la somme des carrés des distances entre chaque point et son centroïde attribué.
Dans Excel :
- Pour chaque point, prenez la distance jusqu’à son centre de gravité et mettez-le au carré.
- Additionnez toutes ces distances au carré.
- Cela donne l’inertie de ce k.
Par exemple:
- pour k = 1, le centre de gravité est simplement la moyenne globale de x1 et x2,
- pour k = 2 et k = 3, nous prenons les centroïdes convergés des feuilles sur lesquelles vous avez exécuté l’algorithme.
On peut alors tracer l’inertie en fonction de k, par exemple pour (k = 1, 2, 3).
Pour cet ensemble de données
- de 1 à 2, l’inertie chute beaucoup,
- de 2 à 3, l’amélioration est beaucoup plus faible.
Le « coude » est la valeur de k au-delà de laquelle la diminution de l’inertie devient marginale. Dans l’exemple, cela suggère que k = 2 est suffisant.

Conclusion
K-means est un algorithme très intuitif une fois que vous le voyez étape par étape dans Excel.
Nous commençons par des centroïdes simples, calculons les distances, attribuons des points, mettons à jour les centroïdes et répétons. Maintenant, nous pouvons voir comment « les machines apprennent », n’est-ce pas ?
Eh bien, ce n’est qu’un début, nous verrons que différents modèles « apprennent » de manières vraiment différentes.
Et voici la transition pour l’article de demain : la version non supervisée du Classificateur centroïde le plus proche est en effet k-signifie.
Alors, quelle serait la version non supervisée de LDA ou DAQ? Nous y répondrons dans le prochain article.



