
Utiliser NumPy pour analyser mes habitudes quotidiennes (sommeil, temps d’écran et humeur)
une petite série de projets NumPy où j’essaie réellement construire quelque chose avec NumPy au lieu de simplement passer par des fonctions et une documentation aléatoires. J’ai toujours pensé que la meilleure façon d’apprendre était de faire, c’est pourquoi dans ce projet, je voulais créer quelque chose à la fois pratique et personnel.
L’idée était simple : analyser mes habitudes quotidiennes – sommeil, heures d’étude, temps passé devant un écran, exercice et humeur – et voir comment elles affectent ma productivité et mon bien-être général. Les données ne sont pas réelles ; c’est fictif, simulé sur 30 jours. Mais l’objectif n’est pas l’exactitude des données : il s’agit d’apprendre à utiliser NumPy de manière significative.
Parcourons donc le processus étape par étape.
Étape 1 — Chargement et compréhension des données
J’ai commencé par créer un simple tableau NumPy contenant 30 lignes (une pour chaque jour) et six colonnes, chaque colonne représentant une métrique d’habitude différente. Ensuite, je l’ai enregistré en tant que .npy fichier afin que je puisse facilement le charger plus tard.
# TODO: Import NumPy and load the .npy data file
import numpy as np
data = np.load(‘activity_data.npy’)Une fois chargé, je voulais confirmer que tout se passait comme prévu. J’ai donc vérifié le forme (pour savoir combien de lignes et de colonnes il y avait) et le nombre de dimensions (pour confirmer qu’il s’agit d’un tableau 2D, pas d’une liste 1D).
# TODO: Print array shape, first few rows, etc.
data.shape
data.ndimSORTIE : 30 lignes, 6 colonnes et ndim=2
J’ai également imprimé les premières lignes juste pour confirmer visuellement que chaque valeur semblait correcte – par exemple, que les heures de sommeil n’étaient pas négatives ou que les valeurs d’humeur se situaient dans une plage raisonnable.
# TODO: Top 5 rows
data[:5]Sortir:
array([[ 1. , 6.5, 5. , 4.2, 20. , 6. ],
[ 2. , 7.2, 6. , 3.1, 35. , 7. ],
[ 3. , 5.8, 4. , 5.5, 0. , 5. ],
[ 4. , 8. , 7. , 2.5, 30. , 8. ],
[ 5. , 6. , 5. , 4.8, 10. , 6. ]])Étape 2 — Validation des données
Avant de faire une analyse, je voulais m’assurer que les données avaient du sens. C’est quelque chose que nous ignorons souvent lorsque nous travaillons avec des données fictives, mais cela reste une bonne pratique.
J’ai donc vérifié :
- Pas d’heures de sommeil négatives
- Aucune note d’humeur inférieure à 1 ou supérieure à 10
Pour le sommeil, cela signifiait sélectionner la colonne sleep (index 1 dans mon tableau) et vérifier si des valeurs étaient inférieures à zéro.
# Make sure values are reasonable (no negative sleep)
data[:, 1] < 0Sortir:
array([False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False])Cela signifie pas de points négatifs. Ensuite, j’ai fait la même chose pour l’humeur. J’ai compté pour constater que la colonne d’humeur était à l’index 5 et j’ai vérifié si certaines étaient inférieures à 1 ou supérieures à 10.
# Is mood out of range?
data[:, 5] < 1
data[:, 5] > 10Nous avons obtenu le même résultat.
Tout semblait bien, nous avons donc pu passer à autre chose.
Étape 3 — Diviser les données en semaines
J’avais 30 jours de données et je voulais les analyser semaine par semaine. Le premier réflexe a été d’utiliser celui de NumPy split() fonction, mais cela a échoué car 30 n’est pas divisible par 4. Donc à la place, j’ai utilisé np.array_split()ce qui permet des divisions inégales.
Cela m’a donné :
- Semaine 1 → 8 jours
- Semaine 2 → 8 jours
- Semaine 3 → 7 jours
- Semaine 4 → 7 jours
# TODO: Slice data into week 1, week 2, week 3, week 4
weekly_data = np.array_split(data, 4)
weekly_dataSortir:
[array([[ 1. , 6.5, 5. , 4.2, 20. , 6. ],
[ 2. , 7.2, 6. , 3.1, 35. , 7. ],
[ 3. , 5.8, 4. , 5.5, 0. , 5. ],
[ 4. , 8. , 7. , 2.5, 30. , 8. ],
[ 5. , 6. , 5. , 4.8, 10. , 6. ],
[ 6. , 7.5, 6. , 3.3, 25. , 7. ],
[ 7. , 8.2, 3. , 6.1, 40. , 7. ],
[ 8. , 6.3, 4. , 5. , 15. , 6. ]]),
array([[ 9. , 7. , 6. , 3.2, 30. , 7. ],
[10. , 5.5, 3. , 6.8, 0. , 5. ],
[11. , 7.8, 7. , 2.9, 25. , 8. ],
[12. , 6.1, 5. , 4.5, 15. , 6. ],
[13. , 7.4, 6. , 3.7, 30. , 7. ],
[14. , 8.1, 2. , 6.5, 50. , 7. ],
[15. , 6.6, 5. , 4.1, 20. , 6. ],
[16. , 7.3, 6. , 3.4, 35. , 7. ]]),
array([[17. , 5.9, 4. , 5.6, 5. , 5. ],
[18. , 8.3, 7. , 2.6, 30. , 8. ],
[19. , 6.2, 5. , 4.3, 10. , 6. ],
[20. , 7.6, 6. , 3.1, 25. , 7. ],
[21. , 8.4, 3. , 6.3, 40. , 7. ],
[22. , 6.4, 4. , 5.1, 15. , 6. ],
[23. , 7.1, 6. , 3.3, 30. , 7. ]]),
array([[24. , 5.7, 3. , 6.7, 0. , 5. ],
[25. , 7.9, 7. , 2.8, 25. , 8. ],
[26. , 6.2, 5. , 4.4, 15. , 6. ],
[27. , 7.5, 6. , 3.5, 30. , 7. ],
[28. , 8. , 2. , 6.4, 50. , 7. ],
[29. , 6.5, 5. , 4.2, 20. , 6. ],
[30. , 7.4, 6. , 3.6, 35. , 7. ]])]Désormais, les données étaient divisées en quatre morceaux et je pouvais facilement les analyser séparément.
Étape 4 — Calcul des métriques hebdomadaires
Je voulais avoir une idée de la façon dont chaque habitude changeait de semaine en semaine. Je me suis donc concentré sur quatre choses principales :
- Sommeil moyen
- Heures d’étude moyennes
- Temps d’écran moyen
- Score d’humeur moyen
J’ai stocké le tableau de chaque semaine dans une variable distincte, puis j’ai utilisé np.mean() pour calculer les moyennes pour chaque métrique.
Heures de sommeil moyennes
# store into variables
week_1 = weekly_data[0]
week_2 = weekly_data[1]
week_3 = weekly_data[2]
week_4 = weekly_data[3]
# TODO: Compute average sleep
week1_avg_sleep = np.mean(week_1[:, 1])
week2_avg_sleep = np.mean(week_2[:, 1])
week3_avg_sleep = np.mean(week_3[:, 1])
week4_avg_sleep = np.mean(week_4[:, 1])Heures d’étude moyennes
# TODO: Compute average study hours
week1_avg_study = np.mean(week_1[:, 2])
week2_avg_study = np.mean(week_2[:, 2])
week3_avg_study = np.mean(week_3[:, 2])
week4_avg_study = np.mean(week_4[:, 2])Temps d’écran moyen
# TODO: Compute average screen time
week1_avg_screen = np.mean(week_1[:, 3])
week2_avg_screen = np.mean(week_2[:, 3])
week3_avg_screen = np.mean(week_3[:, 3])
week4_avg_screen = np.mean(week_4[:, 3])Score d’humeur moyen
# TODO: Compute average mood score
week1_avg_mood = np.mean(week_1[:, 5])
week2_avg_mood = np.mean(week_2[:, 5])
week3_avg_mood = np.mean(week_3[:, 5])
week4_avg_mood = np.mean(week_4[:, 5])Ensuite, pour que tout soit plus facile à lire, j’ai joliment formaté les résultats.
# TODO: Display weekly results clearly
print(f”Week 1 — Average sleep: {week1_avg_sleep:.2f} hrs, Study: {week1_avg_study:.2f} hrs, “
f”Screen time: {week1_avg_screen:.2f} hrs, Mood score: {week1_avg_mood:.2f}”)
print(f”Week 2 — Average sleep: {week2_avg_sleep:.2f} hrs, Study: {week2_avg_study:.2f} hrs, “
f”Screen time: {week2_avg_screen:.2f} hrs, Mood score: {week2_avg_mood:.2f}”)
print(f”Week 3 — Average sleep: {week3_avg_sleep:.2f} hrs, Study: {week3_avg_study:.2f} hrs, “
f”Screen time: {week3_avg_screen:.2f} hrs, Mood score: {week3_avg_mood:.2f}”)
print(f”Week 4 — Average sleep: {week4_avg_sleep:.2f} hrs, Study: {week4_avg_study:.2f} hrs, “
f”Screen time: {week4_avg_screen:.2f} hrs, Mood score: {week4_avg_mood:.2f}”)Sortir:
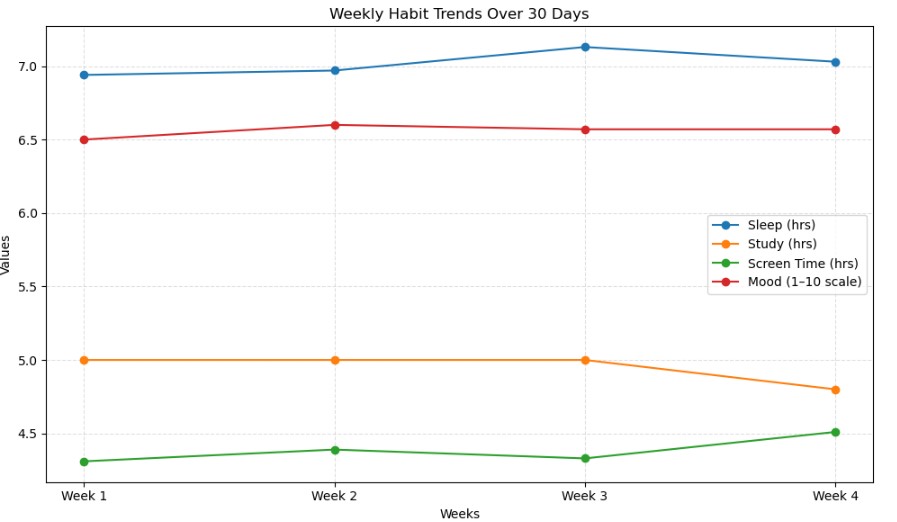
Week 1 – Average sleep: 6.94 hrs, Study: 5.00 hrs, Screen time: 4.31 hrs, Mood score: 6.50
Week 2 – Average sleep: 6.97 hrs, Study: 5.00 hrs, Screen time: 4.39 hrs, Mood score: 6.62
Week 3 – Average sleep: 7.13 hrs, Study: 5.00 hrs, Screen time: 4.33 hrs, Mood score: 6.57
Week 4 – Average sleep: 7.03 hrs, Study: 4.86 hrs, Screen time: 4.51 hrs, Mood score: 6.57Étape 5 — Donner un sens aux résultats
Une fois que j’ai imprimé les chiffres, certains modèles ont commencé à apparaître.
Mon heures de sommeil étaient assez stables pendant les deux premières semaines (environ 6,9 heures), mais au cours de la troisième semaine, ils sont passés à environ 7,1 heures. Cela signifie que je « dormais mieux » au fil du mois. Au cours de la quatrième semaine, il est resté environ 7,0 heures.
Pour heures d’étudec’était le contraire. Les semaines un et deux duraient en moyenne environ 5 heures par jour, mais la quatrième semaine, elle était tombée à environ 4 heures. Fondamentalement, j’ai commencé fort mais j’ai lentement perdu mon élan – ce qui, honnêtement, semble juste.
Puis vint temps d’écran. Celui-ci a fait un peu mal. Au cours de la première semaine, c’était environ 4,3 heures par jour, et cela n’a cessé d’augmenter chaque semaine. Le cycle classique consistant à être productif au début, puis à dériver lentement vers davantage de « pauses de défilement » plus tard dans le mois.
Finalement, il y avait humeur. Mon score d’humeur a commencé à environ 6,5 la première semaine, est allé légèrement jusqu’à 6,6 la deuxième semaine, puis est resté en quelque sorte là pour le reste de la période. Cela n’a pas changé de façon spectaculaire, mais il était intéressant de constater un petit pic au cours de la deuxième semaine, juste avant que mes heures d’étude ne diminuent et que mon temps d’écran n’augmente.
Pour rendre les choses interactives, j’ai pensé que ce serait génial de visualiser en utilisant matplotlib.

Étape 6 — Recherche de modèles
Maintenant que j’avais les chiffres, je voulais savoir pourquoi mon humeur s’est améliorée au cours de la deuxième semaine.
J’ai donc comparé les semaines côte à côte. La deuxième semaine a été marquée par un sommeil décent, des heures d’étude élevées et un temps d’écran relativement faible par rapport aux semaines suivantes.
Cela pourrait expliquer pourquoi mon score d’humeur a culminé là-bas. Au cours de la troisième semaine, même si je dormais davantage, mes heures d’étude avaient commencé à baisser – peut-être que je me reposais davantage mais que je faisais moins, ce qui n’a pas amélioré mon humeur autant que je m’y attendais.
C’est ce que j’ai aimé dans le projet : il ne s’agit pas de données réelles, mais de la façon dont vous pouvez utiliser NumPy pour explorer des modèles, des relations et de petites idées. Même les données fictives peuvent raconter une histoire si on les regarde correctement.
Étape 7 — Conclusion et prochaines étapes
Dans ce petit projet, j’ai appris quelques choses clés, à la fois sur NumPy et sur l’analyse structurante comme celle-ci.
Nous avons commencé avec un éventail brut d’habitudes quotidiennes fictives, avons appris à vérifier sa structure et sa validité, à le diviser en morceaux significatifs (semaines), puis à utiliser des opérations NumPy simples pour analyser chaque segment.
C’est le genre de petit projet qui vous rappelle que l’analyse des données ne doit pas toujours être complexe. Parfois, il s’agit simplement de poser des questions simples comme « Comment mon temps d’écran évolue-t-il au fil du temps ? » ou « Quand est-ce que je me sens le mieux? »
Si je voulais aller plus loin (ce que je ferai probablement), il y a tellement de directions à suivre :
- Trouver le les meilleurs et les pires jours dans l’ensemble
- Comparer en semaine contre le week-end
- Ou même créer un simple « score de bien-être » basé sur plusieurs habitudes combinées
Mais ce sera probablement pour la suite de la série.
Pour l’instant, je suis heureux d’avoir pu appliquer NumPy à quelque chose qui semble réel et pertinent – pas seulement des tableaux et des nombres abstraits, mais des habitudes et des émotions. C’est le genre d’apprentissage qui colle.
Merci d’avoir lu.
Si vous suivez la série, essayez de recréer cela sur vos propres données fictives. Même si vos nombres sont aléatoires, le processus vous apprendra à découper, diviser et analyser des tableaux comme un pro.
You may also like


